


Chapters

Git is a fundamental part of the workflow, but knowing how to get the most out of it is often the Achilles' heel even for experienced developers.
It's impossible to imagine today’s programming without version control systems like Git. As a distributed version control system, Git allows every developer to have a full copy of the project and project history, enabling collaboration without a constant connection to a central repository. They improve the work on code creation in a way that cannot be overestimated.
Many people, especially juniors, however, limit themselves to learning only the most basic git commands, such as commit, push, or pull, and only when they need something more complicated from time to time, they search the Internet or simply ask their older colleagues.
But is it worth remembering the more complicated git commands at all? GUI programs such as GitHub Desktop and GitKraken, deprive us of having to type commands into the terminal, making it seem unnecessary to memorize all these strange shortcuts. The most important thing, however, is the very fact of getting to know the possibilities that git gives us, which many coders are not even aware of.
In this article, I’ll go through the most common git commands, from the basic ones to the more advanced ones.
What are you, git?
Simply put, git is the most popular version control system (VCS for short). it's a tool that allows you to save individual versions of the project and the multiple files it contains so that we can return to them in the future and compare, combine, or manage them. A git repository is a storage space where your project files and their history are kept, making it essential for version control. Importantly, using git doesn’t require an Internet connection - changes are saved locally, on our machine, which allows you to use it in all conditions. Our repositories - repos for short (workspaces with files, which we can track and manage) can be shared and stored on hosting services such as GitHub, which allows for efficient work in development teams on large projects.
Not everything is for everyone
Before we get into the commands, let's discuss one more important thing about git: the .gitignore folder.
In many projects, there are files that we don't want to release into the world - such as those containing API keys, credentials, etc., but also dependencies and packages, operating system files, and others, depending on your needs. For this purpose, a special folder called .gitignore is created, in which you specify which files should be omitted when creating and updating the repository. This folder can be anywhere in the repository but is assumed to be created in the root directory. In .gitignore, we can list specific files, entire folders, or, for example, all files with a given extension. Below is an example of the content of the .gitignore folder:
- file.ts (file.ts will be omitted)
- Files/ (the Files folder and its contents will be omitted)
- *.env -all files with the ".log" extension will be omitted
Repository control
Below I present the most basic git commands related to creating and checking the state of a repository. I assume that git is already installed on your machine. A 'git repo' is a version-controlled repository where you can commit changes, revert to the last committed version, and manage your project files efficiently.
git init
This is a command that is used relatively rarely (only once for the entire project), but I found it worth including here. Git init's of course used to create a repository that will contain all the files contained in the folder in which you're running this command (workspace). A directory .git (a hidden folder) with some subdirectories is also created there.
When the command is called, we get a message with information, that a new repo has been created and with a full path to it.
git status
This command shows the repository status - what branch we're currently on, are there any changes from the previous commit, are untracked files (more on that later), are we up to date with remote branch, etc. If we run this command in a directory where there is no repository, we’ll get information on this as a response.
git log
This command will give us logs of committed commits, including the time of their creation, the person who committed, message, and unique commit hashes.
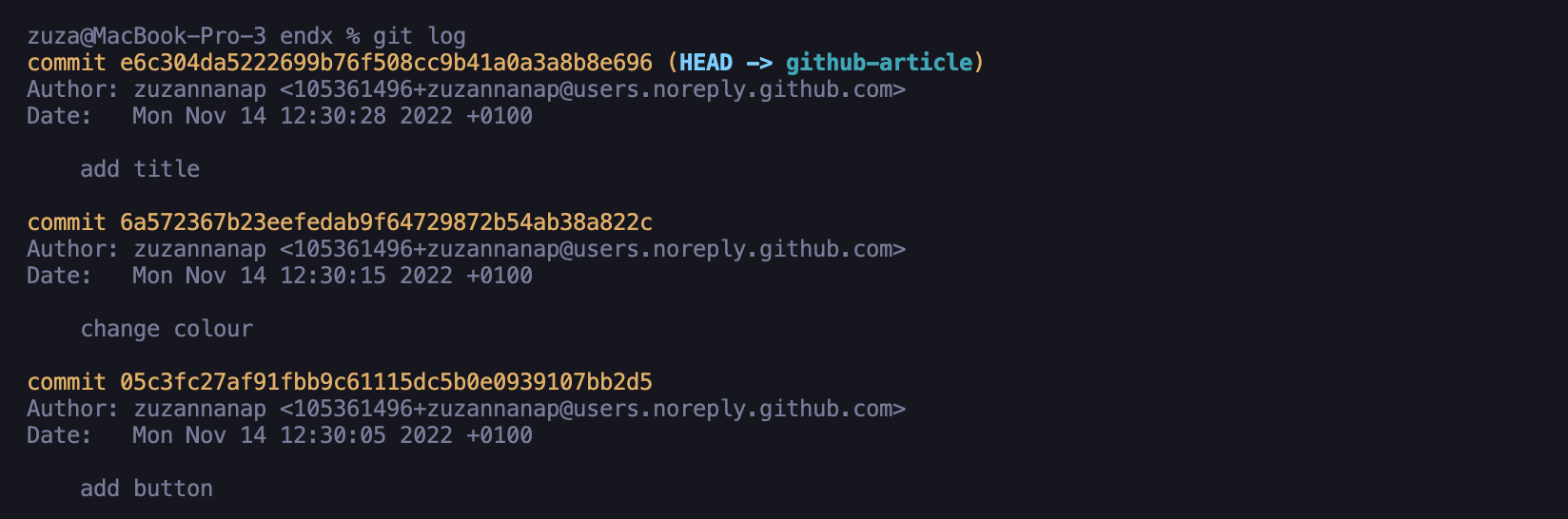
By using additional flags, we can influence, among others, the appearance of logs by using the --pretty flag and the selected format. For example --pretty --oneline will make you only get shortened commit hashes with the first lines of titles (if they have more lines), like in the snapshot below:

Commit after commit
git add
This command is used before git commit. By using it, we can choose which files we want to commit later. Such staged changes form a group of changes that can be saved later in one common commit containing a message describing what has changed in the project. We can add both a single file, multiple files, and all files at once, like below:
- git add file.ts
- git add file1.ts file2.ts
- git add . (this one will add all changed files to staging)
The rest of the changed files will remain untracked. The existence of untracked files and staged files can be checked by using the "git status" command.
git commit
Commit is a registration of the current state of files in the project creation process, confirming the recently introduced and saved changes, to which we can assign a message describing the last changes. Commit represents the changes that have been made to the files selected for the given commit (they don't have to be all the changed files) since the previous commit. It differs from the usual save - if we know the hash (a kind of identifier) of a given commit, at any time we can restore the project to any past committed state in a repo.
The message attached to the commit should summarize the changes contained in the given commit. it's assumed that names are built-in present, not past tense, e.g. "change title styles" or "add submit button". A good commit message should start with a single short line summarizing the change, followed by a more thorough description. We add messages by adding the -m flag with a message in quotation marks: git commit -m "add submit button".
We can also use the abbreviated form: git commit -a -m “message” - this will stage all changes and commit them. The -a flag stages all changes of tracked files and commits them. If we don't add the flag and message to the command and only use git commit, an editor will open and ask us to commit a message to the commit.
Sometimes there may be situations where, after creating a commit, you realize that you didn’t make a change that you wanted to include in it, or, for example, you forgot to add an important file. In this case, the --amend flag will come in handy, as it will undo the last commit and edit it. An editor will then open a file, where you can change the message commit and the files it contains. If you apply any changes before applying the amend flag, they'll be added to the edited file.
An example situation with the usage of git amend:
- git commit -m "add navbar" (at this point we realize that we forgot to add one of the files)
- git add navbarItem.tsx (now only navbarItem.tsx is staged)
- git commit --amend (all files from the previous commit and navbarItem.tsx are staged and the editor opens)
On the branches of the git working tree
When we use git, we’re always on a branch. If we did not create any additional branch ourselves, we're on the so-called branch master (or main) - the default branch that is created automatically when the repository is created.
Branches are used when working on various project areas at the same time. Thanks to them, each person can deal with something else, e.g. while one prepares a form, the other is creating a navbar, and the third - authorization, and everyone is completely independent. Git branches allow users to create a new feature without affecting the main project. To create a new branch, you can use the git branch command, and to switch to the new branch, use the git checkout command. When a given part of the project is finished and we want to add it to the project (and we can wait as long as we want, for example, while waiting for the official introduction of a given functionality), the minor branch is attached to the master branch (or other selected branch), without affecting other branches in the project. Git makes sure that no conflicts arise in the code, and if they do occur, it communicates the need to resolve them.
main or master?
When we start creating a repository on GitHub, the default branch will be called main, not master. This has been the case since October 2020, when the company decided to remove the potential risk of linguistic associations and references to slavery in pair with the word "master". Anyway, git stayed with the name "master".
What is HEAD?
HEAD is a point that marks where we're currently in the repo. It specifies the branch we're on, and the branch points to a specific commit - so we can say it’s a reference to a specific branch that points to a specific commit. In practice, this is a place in the repository that is currently open and we can browse through it.
So much for the theoretical background. Below I present the most important commands related to branches.
git branch
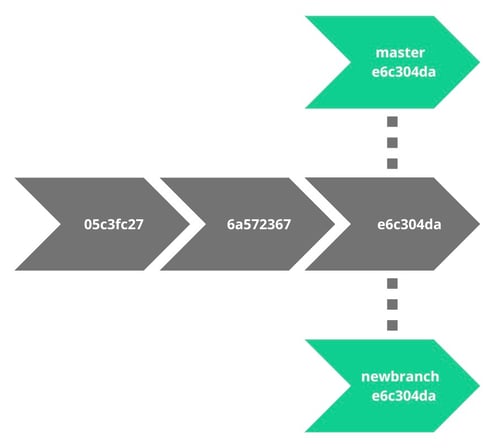
It's a command that displays the names of all existing branches of a given repository with the distinction of the branch on which we're currently located. This 'git branch' command is a fundamental git command used for branch management.
If we add something else after the command, then a branch with this name will be created, e.g. git branch dark-mode will create a new branch called dark-mode, containing the same code as HEAD. The current commit will be assigned to both branches. The command does not transfer the newly created branch (HEAD is still on the branch we were on by running the command).
We'll use the same command with an additional -d flag when we want to delete a branch. git branch -d <branch-name> will remove the selected branch from the repo. Such an operation must be performed from another branch - you cannot delete a branch you're currently on.
If the branch that we want to delete has not been pre-merged with another branch, git will warn us about it. If we still want to delete a branch, we can use the --force flag or use the -D flag instead of -d (as can be deduced, -D works like combining the -d with --force).
There is also a flag for renaming a branch: -m. When using it, we must be on the branch that we want to rename. Git branch -m <new-branch-name> will change the name of the current branch to the new one.
Another useful flag might be -v. git branch -v will show us a truncated list of branches with the name and a shortened hash of the last commit on each of them.
git switch
When we enter git switch <branch-name> in the terminal, we’ll be transferred to the selected branch, and HEAD will be on the latest commit on that branch. Git switch without any branch name and will take us to the branch we were on before moving to the current one. Before we change the branch, however, we need to make sure that all changes on the branch we're leaving are committed - if they’re not, git will inform us about it. However, if the only changes we made to the branch are for newly created files, git will allow us to change the branch without losing those changes - it'll be possible to stage and commit on the branch we go to.
In one expanded command, we can create a new branch at once and move to it. Git switch -c <new-branch-name> will create a branch and move us to it immediately.
git checkout
Git checkout <branch-name> also takes us to the selected branch, but it also has additional features that you can read about in the official documentation (of course you can read there about all git commands). This command also has a flag that allows you to create and move to a branch at the same time: -b. The whole command will look like this: git checkout -b <branch-name>.
Git checkout <commit-hash> will move the HEAD to the selected commit. At this point, a detached HEAD will be created, because HEAD will then point to a specific commit, not a branch. Before checking out a specific commit, you can use the git log command to view commit history. Instead of using a hash, we can also refer to a reference against the HEAD, e.g. git checkout HEAD ~ 1 will take us to one commit just before HEAD.
It's also possible to move only relative to a single file - for example, if we made changes to several files, but we want to go back to the state from the previous commit for only one file, we can use git checkout HEAD <filename> to discard changes made in this particular file.
Connecting branches
The incredibly important thing about git is how you can connect different branches - that's what you create them for - to make changes that can later be introduced into the main code. Connecting branches can be done in various ways, e.g. through merge, pull, or rebase commands.
git merge
Git merge allows you to join code from another branch to the branch you're currently on. The HEAD from the current branch is then linked to the last commit from the merge branch. If both branches have commits that don’t appear on the other branch, then the merge commit will have 2 parents.
During a merge conflicts may appear- for example, if we change the same code fragment both on the branch we're on and on the branch we want to merge into it, git won’t know which version of the file we want to keep. In this case, we'll be asked to resolve the conflicts. It can be done manually or using editor tools.
git diff
Thanks to this command we can see changes between branches, commits, files, remote and local branches, or working directories. In the output we’ll see:
- compared files
- metadata
- markers in the form of pluses or minuses
- modified parts of code with unchanged parts right next to them with the header saying from which line and how many lines were changed
Git diff without any flag will show all the changes from the previous commit that are not staged. Git diff HEAD will show staged and unstaged changes that were made since the last commit. Git diff --staged or git diff -cached show only staged changes.
If we add the name of a file at the end of those commands, we'll see only changes made to that specific file. It’s also possible to see the differences in files between specific commits or branches. To compare them we have to use git diff <first>..<second>.
git stash
There are situations when we made some changes to the branch since the previous commit and we want to switch to another branch for a moment, but creating a new commit on the branch would be a bit pointless. Sometimes a switch is possible in this situation, but if there are any conflicts, git won’t allow it. This is where git stash comes in handy - this command hides uncommitted changes for a while and allows you to restore them later. Git stash save does the same as git stash, while git stash pop removes changes from stash and restores them, allowing them to be committed.
An additional option is git stash apply, which works like git stash pop, but doesn't remove changes from stash, so we can pop or apply them later on another branch.
We can use the stash several times in a row without using git stash pop - changes will be added to the stash in the correct order. Through using git stash list we can see the history of our changes, and through git stash apply <stash-id> we can apply changes from the selected stash.
If we want to remove a particular stash from the list, we'll do so with git stash drop <stash-id>.
Repairing past mistakes
In addition to the possibility of going back to commits from the past, e.g. using git checkout, there are also commands created specifically to undo changes.
git restore
This is a relatively new command, introduced for ease of use, just like git switch. Git restore <filename> works the same as git checkout HEAD <filename>, so it restores the selected file to the state it was in at the last commit. If we use the --source flag, we can restore the file to the state from any selected commit, using a reference in the form of hash or references to HEAD, e.g. git restore --source HEAD ~ 2 <filename>.
Git restore has a special --staged flag, which gives this command an additional use - unstaging of the staged changes. Git restore --staged <filename> will remove staged changes of the given file. Contrary to the situation after using restore itself, changes made to files, in this case, won’t be lost, and will only be deleted from staging.
reset or revert?
Git reset and git revert sound and work quite similarly, so it's easy to make a mistake when using them - you have to be careful as there are significant differences between them.
Git reset is similar to git restore but applies to the entire repository, not a specific file. Git reset <commit-hash> will delete commits that were created after the selected commit. However, the changes to the code will not be removed and it will be possible to commit them again. If we add the --hard flag to the command, all changes made to files from the selected point in the repository history will be deleted together with the commits.
Git revert is very similar to git reset, except that it creates a new commit with the code you want to revert to. While git reset only moves HEAD to commit from history, removing all others after him, git revert sets HEAD to the newly created commit (which we'll have to give a message). When working with other people, it doesn't interfere with the commit history that someone may already have locally - instead, it creates a new commit. If we’re sure that collaborators do not yet have the part of the code we want to remove, feel free to use git reset.
Real-life workflow: remote repos
Apart from private initiatives, projects are usually worked on in development teams, so cooperation between coders is necessary. When we work on a remote repository, we must additionally focus on how the changes we make to the code will affect the work of other team members. That is why it's so important to know the options that git gives us when working with remote repositories to have the least negative impact on the work of our colleagues. Below I describe most of the commands used in the developer's everyday work.
How to start with a remote repository?
To start working on a remote repo, we first need to create it (however, the method of its creation will not be described in this article - it will be different depending on the website we use). GitHub and Git facilitate collaboration and version control by allowing multiple people to synchronize code, track project history, and interact with the repository's history. If the repository is already created, we can start working in different ways, depending on whether we connect to an already existing remote repository or if we want to push to a remote already created repo that exists on our computer.
git clone
This is, in a way, the equivalent of git init for a remote repository - by calling git clone <repository-url>, we download an existing repository so we’re able to start making changes to it on our machine.
git remote
If we already have our local repository and we want to make it available to other people, then after creating a remote repository on the selected site, we need to connect our local repo to it - we need to tell git where to push our code. The destination URL where our remote repository is located is commonly called remote. To create a remote there is a command git remote add <remote-name> <remote-url> command. One local repository can be attached to many remote-urls and vice versa (which is why they're given different names). If we want to see a list of our repo's remotes, we can use git remote -v. To push code to the remote branch for the first time, we need to use git push -u <remote-name> <branch-name>. When applying the git clone, a remote branch will be automatically assigned.
We rarely want to rename a branch, but if we do, then git remote rename <old-name> <new-name> will do it. If we want to remove the remote we can use git remote remove <remote-name>.
git push
git push, in addition to connecting the local branch to the remote one, is used to push local changes to the remote branch assigned to it. However, it’s possible to push changes to another remote-branch via git push <remote-name> <local-branch-name>: <remote-branch-name>.
What is a remote tracking branch?
It’s a reference to the last point in the history of the remote branch known on your machine. It’s marked as <remote-name>/<branch-name>, e.g. origin/master. Right after we download the repository or push the changes to the branch, the HEAD, and remote tracking branches indicate the same place in the repository. However, after creating any local commit, the remote-tracking branch stays behind our local repo. We can check this using git status. After pushing the changes to the remote branch, the branches will align again.
The git branch -r command will show us the name of the remote tracking branch we're tracking (with the name of the branch we're currently on).
As soon as the repository is cloned, our local workspace already knows about all remote branches on the given remote and they'll be displayed after using git branch -r. However, these branches won’t be in our local repository yet. To create a local branch that maps the contents of a remote tracking branch and connect it to this remote branch, just use the git switch <branch-name> command (note! git checkout <branch-name> won’t work here - it would only take you to the detached HEAD) .
In teamwork, we often deal with a situation where collaborators push something to a remote branch, which we also use (usually master or main). In these situations, the git fetch and git pull commands are used.
git fetch
To find out that someone else has made changes to the remote branch, use the git fetch <remote-name> command. The changes from the remote repository will then be downloaded and available for review, but without interfering with the code we’re working on - the changes will be made on the remote tracking branches (before we fetch or pull, the remote-tracking branch does not have to be up-to-date with the remote version - it doesn’t track changes itself). If the remote name is not specified, the changes from the origin will be taken from the default. Adding a branch name to the end of the command will download changes only from that branch.
git pull
This command, like git fetch, fetches changes from the remote repo but updates HEAD with them as well. You can say that it’s a combination of fetching and merging, which we call through git pull <remote-name> <branch-name> (or more often just git pull, which will take a remote branch with the same name as the default value as this one, which currently has HEAD and origin remote). In this case, it’s important what branch we’re locally on because the changes will only be attached to it. The branch name in the command specifies which remote branch is to be included in our HEAD. As in an ordinary merge, conflicts may arise in this case, which we'll have to resolve.
The pull is also needed when we want to push some changes to a branch that someone else pushed something on before us - thanks to this we'll merge changes of our collaborator to our local branch and only then we'll push it to a remote branch. Without pull, git wouldn't let us push changes in such a situation. Additionally, a pull request (PR) is often used in collaborative workflows to propose, discuss, and review changes before merging them into the primary branch.
git rebase
This is a much less used command that some programmers even avoid. It’s a kind of alternative to the use of git merge (or git pull, which includes git merge). When we use git merge, for example, to include the main branch in our branch, when someone makes some changes to it, a new merge commit on our branch is created. If, for example, while on our branch created from the master branch, we use git rebase master instead of git merge master, then all master commits existing on the branch will appear on our branch, and our commits will be rewritten and attached only AFTER them. Thanks to this, we'll get a linear project history that will be simply more readable. Of course, rebase, as well as merge, can cause conflicts that we’ll always be asked to resolve.
When doing a rebase, one thing must always be remembered - never rebase commits that have been pushed to remote and then downloaded by another collaborator, because the commits that would be rebased would still be on his branch (with changes he made) and getting out of this mess could be really hard! Therefore, always before rebasing make sure that everyone has pushed their changes to the branch on which you want to make a rebase.
There is also the -i flag, which allows the so-called interactive rebase that allows rewriting the history of commits and for example deleting, renaming, or reordering them. Rebase refers to the branch the HEAD is currently on. After entering the command git rebase -i <numbers-of--commits-from-HEAD>, e.g. git rebase -i HEAD ~ 2, the list of commits up to the selected place in the history will be shown. This list can be edited using special commands to perform operations (the list of commands will also be included in the file). All commits at the beginning will have a "pick" command in front of them, which means leaving the commit unchanged. We can change it into, for example, "drop" (such a commit will be removed) or "reword" (which after saving the list will lead us to the file, where we'll be able to change the message commit). There are more actions, and all of them are listed in the rebase file. Some of the more useful are squash and fixup, which allow you to squash several commits into one bigger one. Any commits that were created later than the changed file will be rewritten by new commits.
The above commands are only a few of the available and subjectively selected from a much wider range of git possibilities. Nevertheless, there is a high probability they're able to meet most of the needs in the daily work of a programmer.
GUI
Git can also be used by GUIs - specially created programs, such as GitKraken or GitHub Desktop, as well as built-in code editor functions. I won’t develop this topic further in this article, but it’s worth getting acquainted with the possibilities offered by GUI solutions and choosing the most subjectively convenient way of working with git.
Summary
In addition to the above-mentioned features of git, there are many other, less frequently used commands, but it wouldn’t be possible to describe them all in one article. The ones that have been discussed, however, should be enough for you for effective, everyday work, without having to distract your colleagues from work every now and then to ask for help in navigating the git… Good luck!
Check out also:
- Web Accessibility - How to Design Websites and Write Code for Everyone - Learn about what web accessibility is, why it's important, and how to design and code websites that can be used by everyone.
- Making Your Project's Setup Easier and Cheaper with Generic Templates and Monorepos - The big guys are not wrong when they're using monorepos for their projects.
You may also like



We’re available for new projects.
