

Chapters

Building an API? Your mind is probably instantly jumping towards the standard for API creation: REST. But with a growing popularity of GraphQL it is good to know both of them to decide what's better for your project.
REST vs GraphQL - in this article we will look at the pros and cons of both technologies to help you understand them better.
If you are a junior developer, and have no idea what the fuss is all about, this article will shed some light on the basic differences, and pros & cons of using each one. Hopefully, this article will also help you to find out when to use GraphQL for your project.
A brief intro to REST
In 2000, a group of experts led by Roy Fielding, invented REST. It stands for “Representational State Transfer”, and it is an architectural style for an app programming interface. Simply put, it’s a set of rules that developers follow when they create their API. This helped uncover the full potential of web APIs.
Why is REST so popular?
What makes REST popular is that it provides developers a really handy way to fight software complexity problems. It’s user-friendly and easy to understand for the developers to code on.
The Short History of GraphQL
GraphQL is a query language for APIs. Back in 2012, Facebook started it as an internal project. It was created due to the need for better flexibility and efficiency in client-server communication. The main goal was to overcome data fetching issues in their native mobile platform. In 2015 Facebook open-sourced GraphQL. GraphQL gained popularity in the last few years and is a powerful alternative to REST. Many companies like Facebook, PayPal, Twitter use GraphQL in their products.
The Idea Behind REST and GraphQL
REST embraces the concept of having multiple endpoints that react to different HTTP methods.
GraphQL is protocol agnostic. Because of its popularity HTTP is the most common choice client-server protocol when using GraphQL. Therefore, in this article, I will refer to GraphQL served over HTTP.'
GraphQL works with one endpoint which is always reached with a POST request.
What is a REST API?
REST is a standardized software architecture style. It’s the most popular approach to build APIs. It relies on stateless client-server communication protocol which almost always is HTTP. Basically, it means that the main building blocks of the REST API are the structured request sent from the client to the server and the response received back from the server.
REST HTTP Methods
HTTP stands for The Hypertext Transfer Protocol. It is designed to provide communication between clients and servers. HTTP works as a request-response protocol between a client and a server.
GET is used to request data from a specified resource.
POST is used to send data to the API server to create a resource.
PUT is used to send data to the API to update a specific resource.
The PATCH method is used to apply partial modifications to a resource.
The DELETE method serves to delete the specified resource.
Below, you can see a client-server communication with multiple endpoints for one resource.
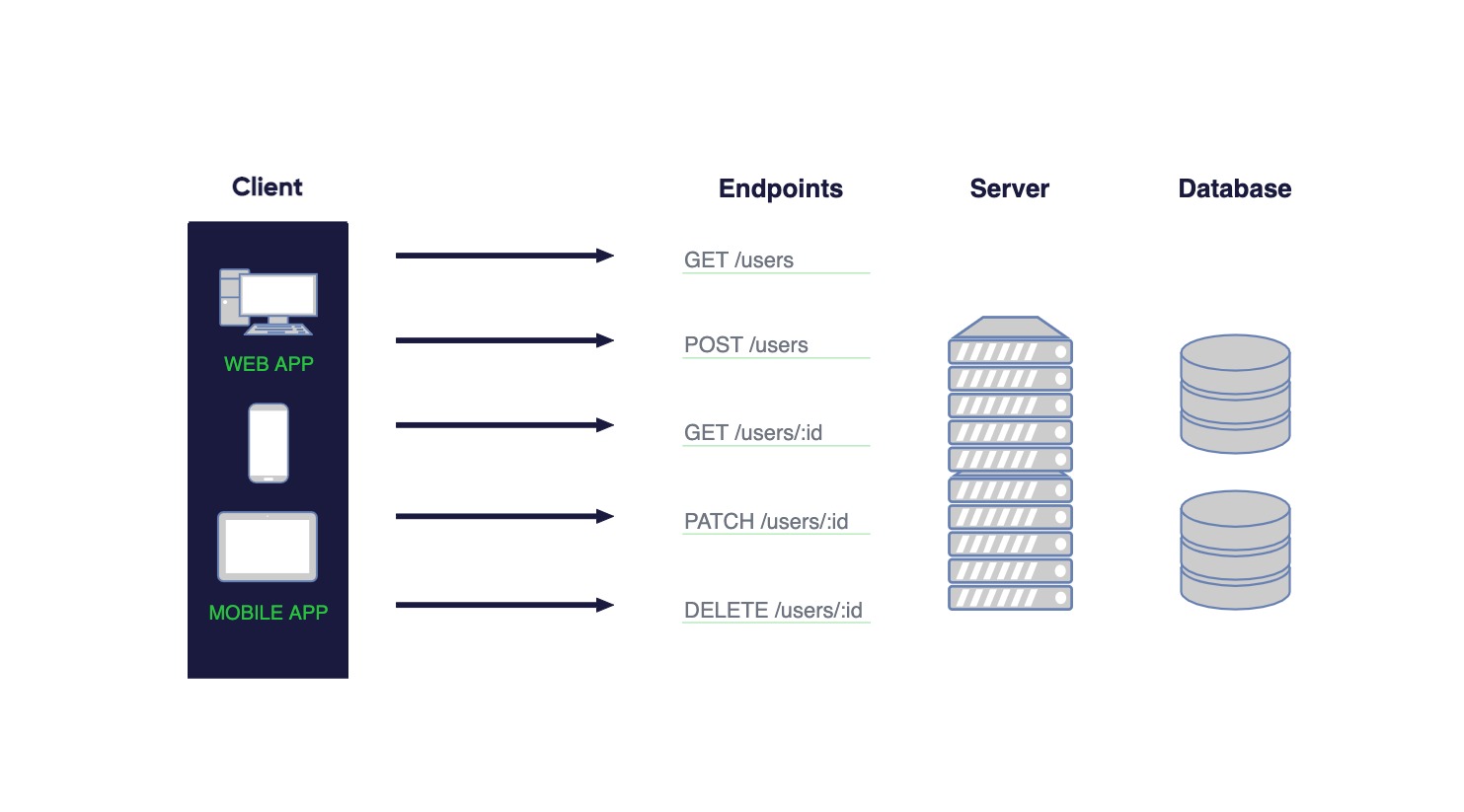 Endpoints are the URL or URI that the HTTP requests are sent to.
Endpoints are the URL or URI that the HTTP requests are sent to.
REST endpoints typically look like this:
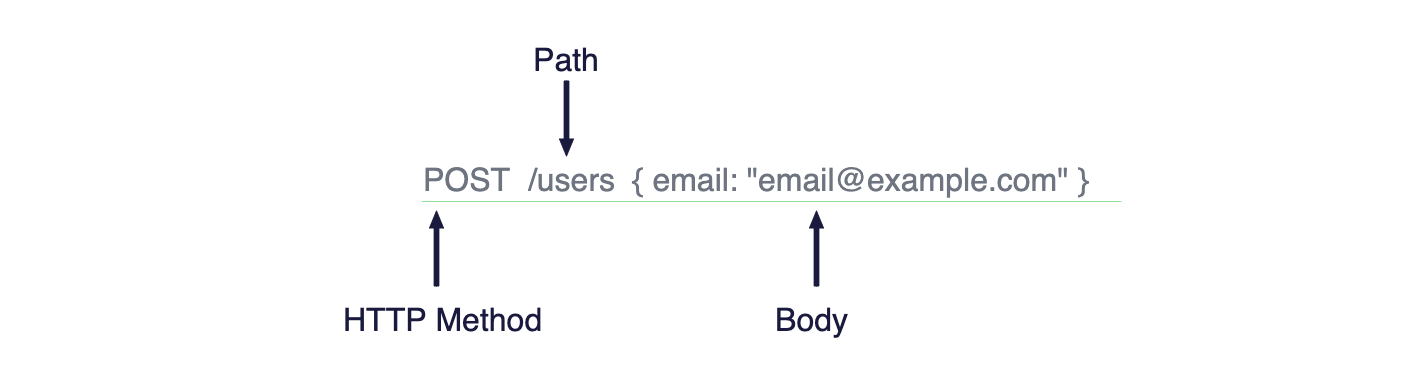 The request has to be structured with a certain HTTP method, a certain path, and possibly a body.
The request has to be structured with a certain HTTP method, a certain path, and possibly a body.
How does GraphQL work?
As I mentioned, in GraphQL there is no need to target multiple endpoints. It has one endpoint which can have any path.
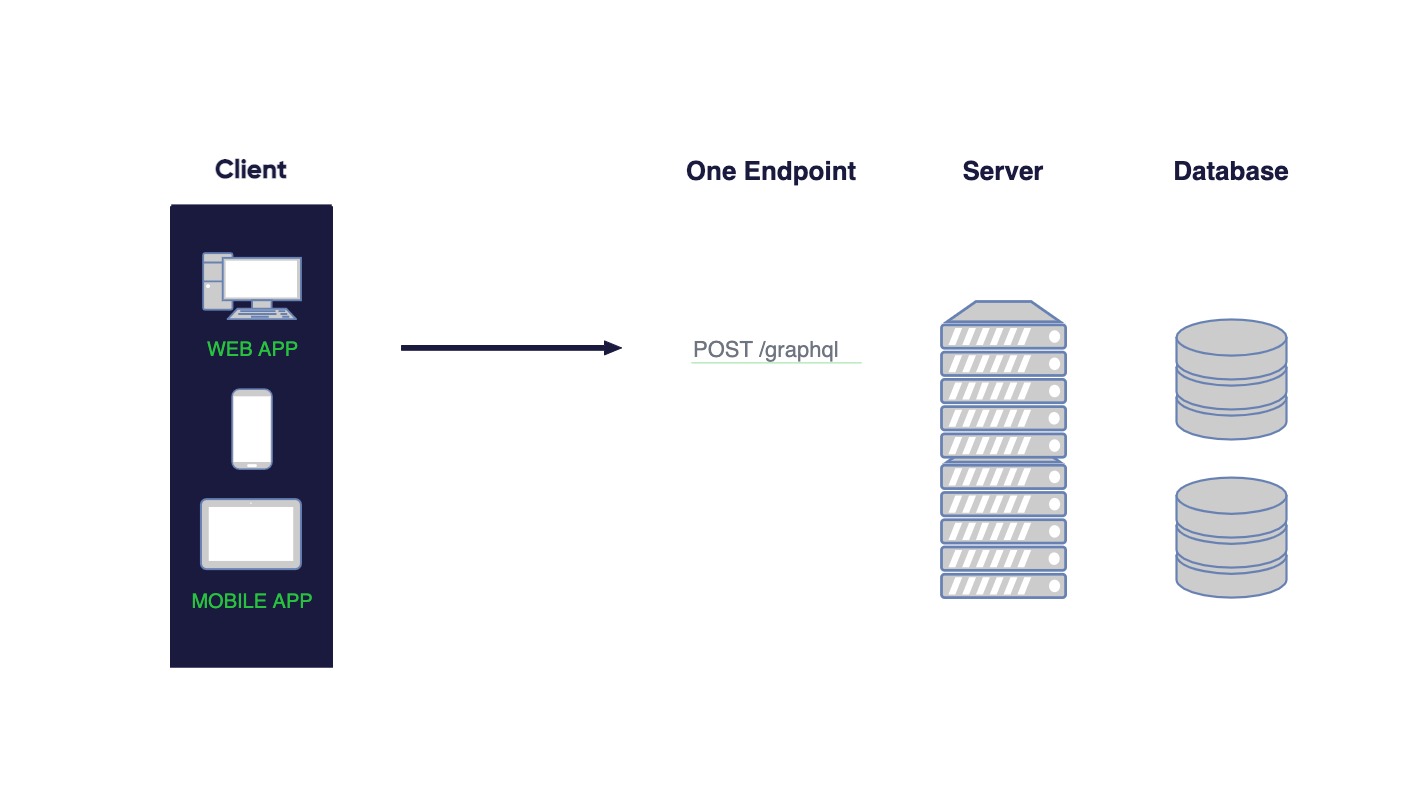 Standard GQL endpoint looks like this:
Standard GQL endpoint looks like this:
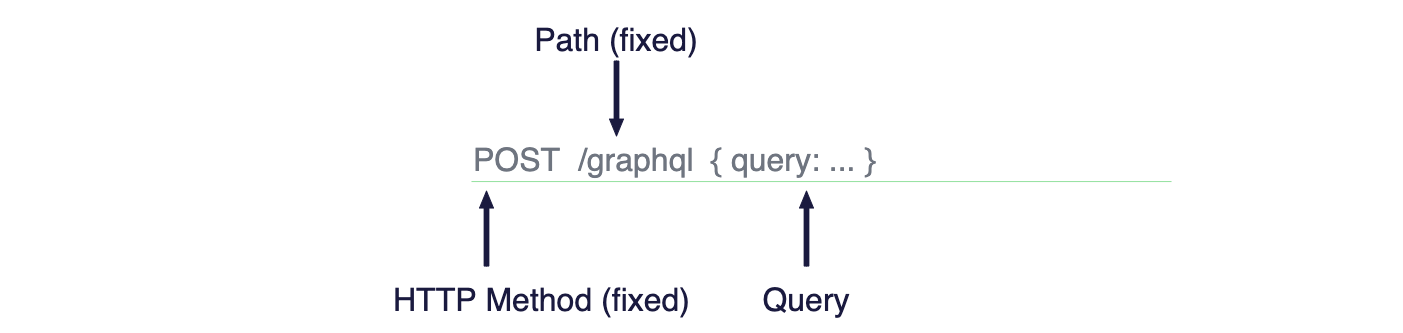 POST request contains query expressions to define the data that should be returned.
POST request contains query expressions to define the data that should be returned.
This is how the typical GraphQL query looks like:
query {
users {
firstName
lastName
age
}
}
The answer matches the request query. A GraphQL operation determines the shape of its data response. Every field in the query becomes a key in the answer object, and the key value is that field's answer. Put simply, it responds with exactly what the client asked for.
GraphQL Schema
GQL schema should have types for all the objects that it uses. We can say that the schema acts as a contract between the client and the server. This means that the code is predictable and it enables smooth development.
It takes a fundamentally different approach to APIs when it comes to REST. Instead of relying on HTTP constructs, it layers a query language with a type system.
Scalar fields are the basic types in GraphQL schema. They represent values like strings, floats, booleans, or integers. ID is a unique identifier that can be used to re-fetch an object or as the key for a cache.
Complex fields are lists that contain objects of certain types.
This is how complex types are defined in a typical GraphQl schema:
type User {
id: ID
firstName: String
lastName: String
age: Integer
}
Type User is a complex object with its characteristics. It contains an ID, firstName, and lastName of type String, age of type Integer.
GraphQL fields, both scalar and complex ones, are modeled after functions. On the server-side, you have to write functions to determine the value returned by every field. We call these functions the resolver functions. Each field of your GraphQL types needs a corresponding resolver function (named as the field).
 A schema can also contain Query and Mutation types. The query represents what the client is asking for, and the mutation when they are going to add or delete data from the API.
A schema can also contain Query and Mutation types. The query represents what the client is asking for, and the mutation when they are going to add or delete data from the API.
type Query {
user_details: [User]
}
type Mutation {
addUser(firstName: String, lastName: String, age: Integer): User
}
Query and Mutation types are defined just like the other types in GraphQL.
The similarities between REST and GraphQL
In both, you typically exchange JSON data. You can use any server-side language and framework and also any front-end language and framework.
The differences between REST and GraphQL
Endpoints
The core difference between these two kinds of APIs is how you send requests to them. In REST there are multiple endpoints.
As the API’s creator, you can easily decide which endpoints are available. If you send a request to a path or with an HTTP verb that is not supported, you will get an error.
Most of the REST APIs return everything available in the dataset for this endpoint. However, it is possible to design the endpoint that returns only specific fields in the response based on a parameter included in the request.
Endpoints can easily get out of control as our datasets expand. This leads to multiple round-trips and causes delays in response time.
In GraphQL, there is only one endpoint.
Fetching data
With REST you retrieve all resources with all data that belong to a resource. Of course, you can implement pagination to limit the amount of data but that adds more complexity to the API. We face the problem of fetching more data than is necessary.
The advantage of GraphQL is that you can be very specific about the data you want to retrieve. It can also retrieve many resources in a single request. The biggest perk of using GraphQL is its declarative data fetching approach. GraphQL clients are in control of the data they need. They declare it to the servers and the server will comply as long as the declaration is valid.
HTTP status
GraphQL queries always return HTTP status 200, regardless of whether the query was successful. When using REST you can build a monitoring system based on API responses. You can also manage the high load with help out of HTTP Proxy Server and cache.
Caching
A simple GraphQL server comes without a built-in caching or batching mechanism. Think about the case when you have to handle complex queries with many nested fields. This can cause serious issues with the application loading time.
Versioning
In every project we have to handle changes in a secure way. It’s crucial to ensure that we’re not breaking the client’s existing calls.
In REST APIs versioning is the way to indicate that you’re making a breaking change to the implementation. There are many versioning strategies. The most commonly used are versioning through URI Path or using Custom Request Header.
In GraphQL Best Practices you can read:
“While there's nothing that prevents a GraphQL service from being versioned just like any other REST API, GraphQL takes a strong opinion on avoiding versioning by providing the tools for the continuous evolution of a GraphQL schema.”
So, instead of versioning GQL creators propose to evolve the schema. The simplest process usually starts with re-implementing the field using different name. Next, we need to ensure that the client's requests use the new field instead. Finally, we remove unused fields from the schema.
Other
Since in GraphQL there is no built-in solution, the developer also needs to handle pagination and authorization.
Unlike GraphQL, the great advantage of REST API is that it's pretty clear and easy to understand. It’s highly scalable, simple, and easy to modify and extend.
REST vs GraphQL - summary
The conclusion is as usual: it all depends. There is no one ultimate approach to build APIs.
GraphQL APIs seem to be a great choice if it comes to the private (consumers and producers of API owned by the same organization) and partner (shared with limited partners) APIs. The interesting thing is that even Facebook which invented GQL uses it for internal APIs (IOS, Android, web app, and how they communicate with Facebook). When it comes to public APIs they usually use REST-based HTTP.
One thing to remember: API is nothing but a delivery mechanism.
At the beginning, we always think about the product considering the value that we want to deliver and to whom we are delivering it. This is a great starting point to think about which approach to choose. It’s not so much to decide which one is better, it’s more about what the context is like. In the end, as always it comes also to personal preferences and experience.
See also
- Naming 101: Programmer's Guide to Naming Things. It’s proven that we spend more time reading code than we do writing it, so you can be sure that good naming will pay off in the future.
You may also like



We’re available for new projects.
