
Oxla
Erstellung von Big Data-Migratoren für die schnellste verteilte Datenbank der Welt

Expertise
Custom Software Development
Platforms
Cloud
Industry
Data Processing

Tools
-
![nest-js]()
NestJS
-
![nodejs@3x]()
NodeJS
-
![typescript@3x]()
TypeScript
-
![react]()
React
-
![docker@3x]()
Docker
-
![sqlite]()
SQLite






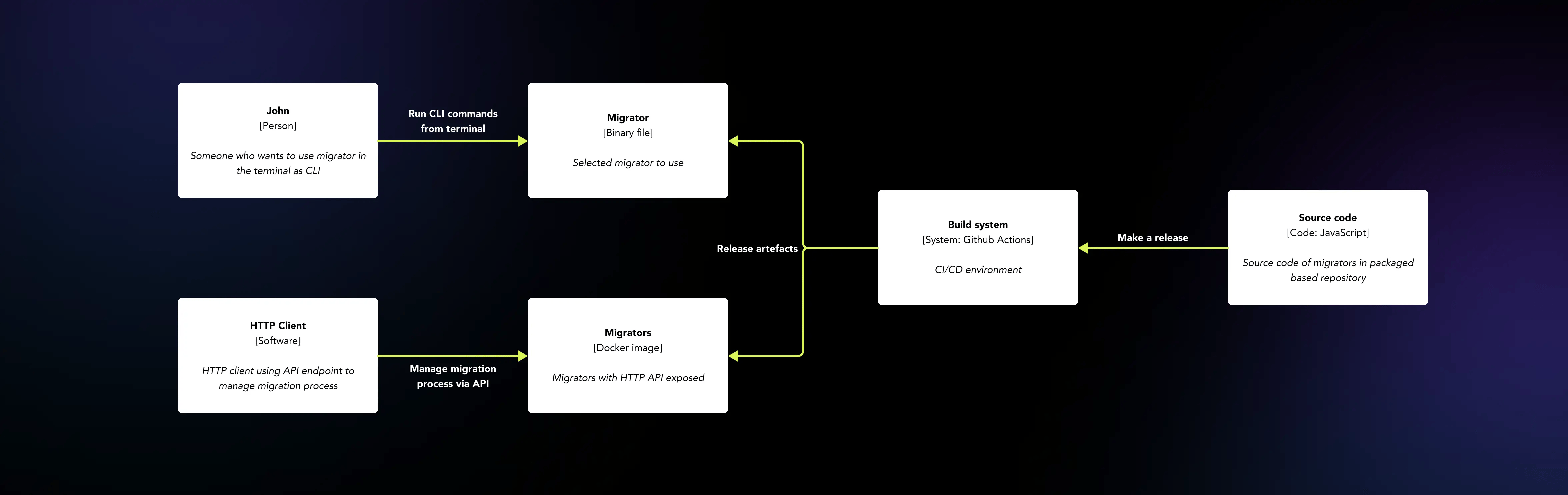
Deliverables
-
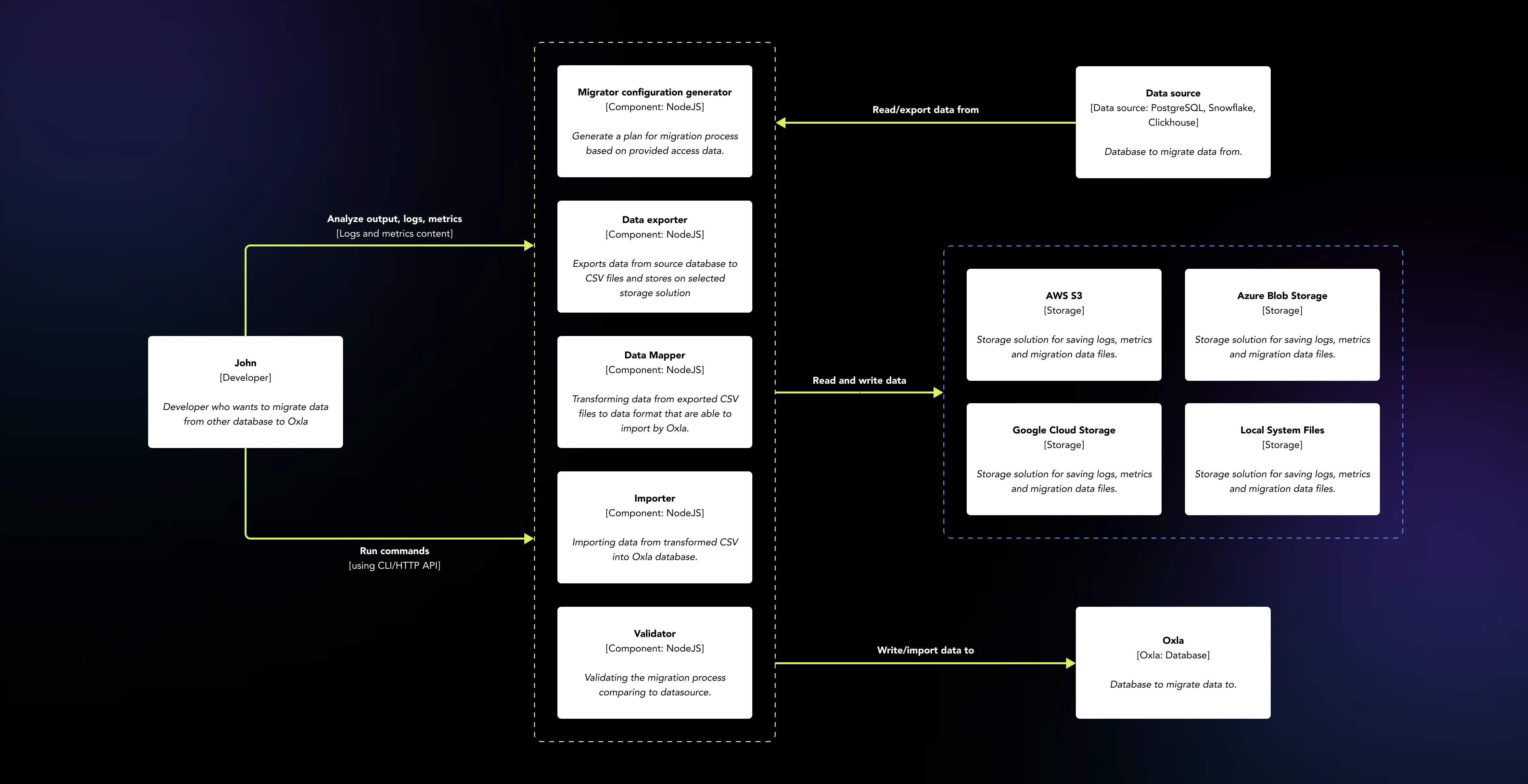
Binärdateien - jeweils eine für jeden Migrator-Typ (Snowflake, PostgreSQL, Clickhouse)
-
Docker-Images mit eingebettetem ausführbarem Migrator.
-
HTTP API für Migrationen als Docker-Image
-
Integration mit verschiedenen Cloud-Speicherlösungen: Google Cloud Storage, AWS S3 Storage und Azure Blob Storage
-
Detaillierte Protokoll- und Überwachungsdaten, die mit SQLite gespeichert sind.
-
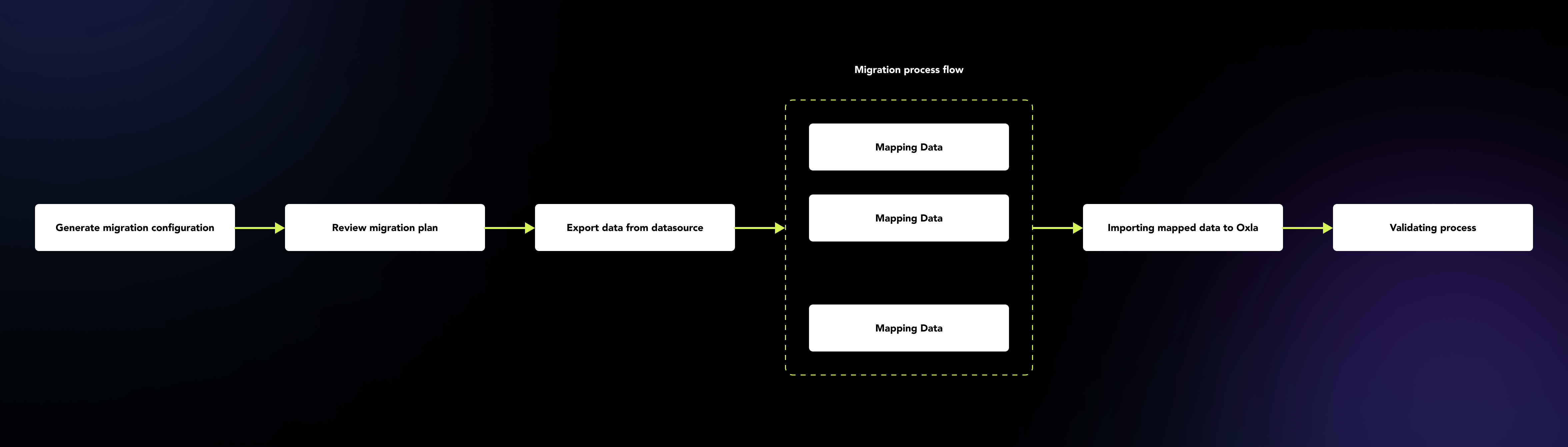
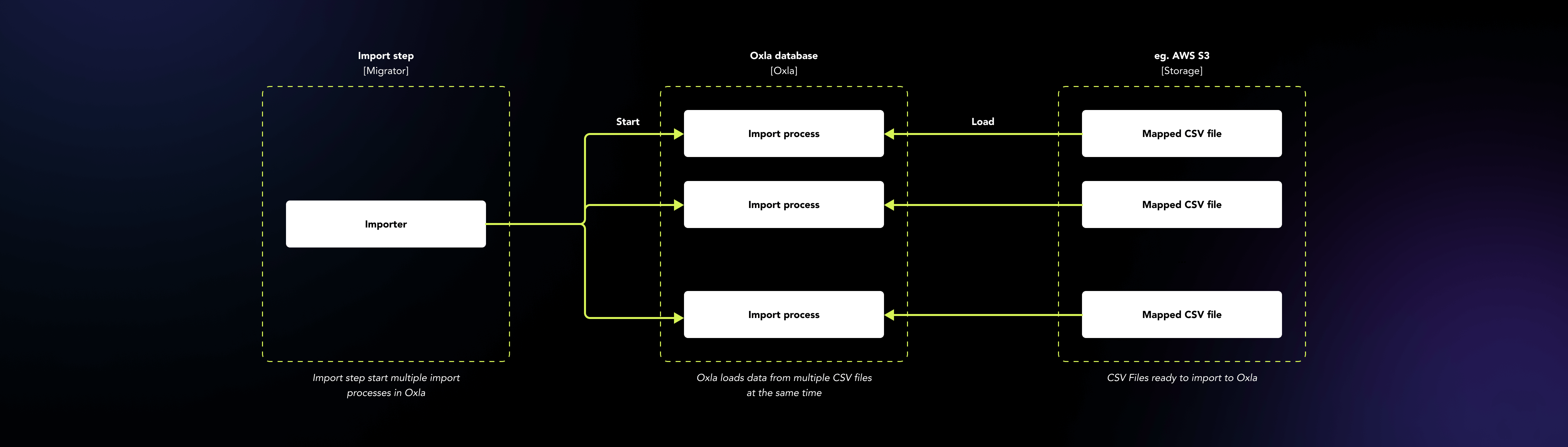
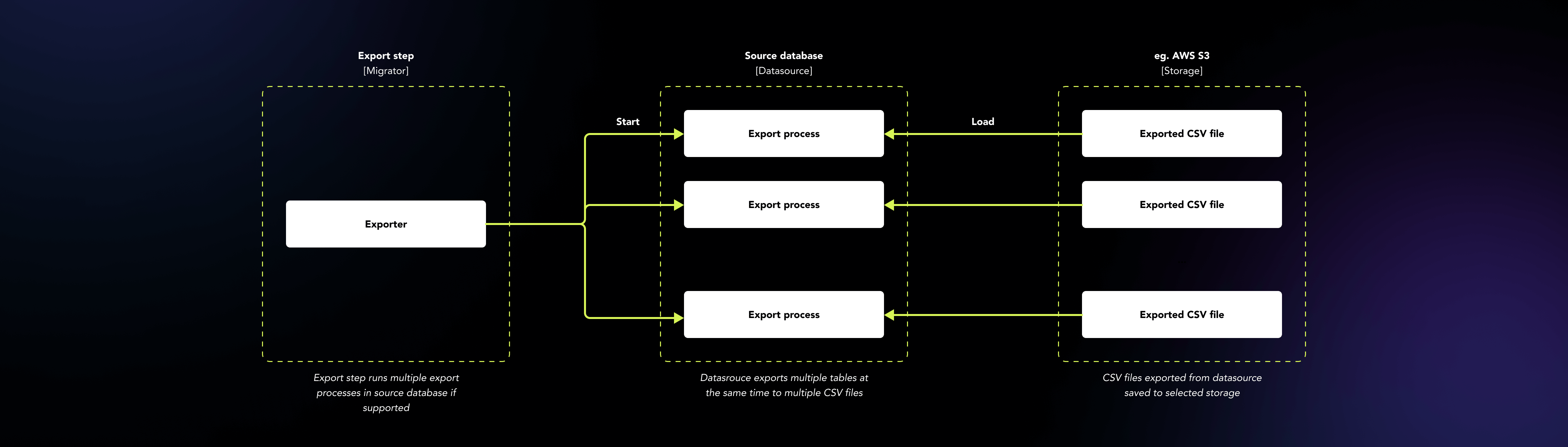
Parallele Verarbeitung von Daten Dateien
Wir sind für neue Projekte verfügbar.

Ähnliche Fallstudien



Want to see more? Check out more of our case studies!
Alle Fallstudien anzeigen