
Chapters

Programmierer verwenden TDD, um die Qualität und Zuverlässigkeit des Codes, den sie erstellen, zu gewährleisten und den Prozess seiner Erstellung zu verbessern. Allerdings achten sie nicht immer darauf, dass das Schreiben von Tests selbst mehr oder weniger optimal sein kann.
TDD (Test Driven Development) geht davon aus, dass Sie mit dem Schreiben von Code beginnen, indem Sie Tests erstellen, die die Anforderungen der Geschäftslogik erfüllen, und dann deren Implementierungen im Anwendungscode erstellen. Diese Annahme scheint einfach, aber damit dieser Ansatz so viele Vorteile wie möglich bringt und den Prozess optimiert, anstatt ihn zu behindern, sollten Sie sich an seine Regeln halten und über Dinge nachdenken wie was Sie tatsächlich testen möchten, was Sie von einer bestimmten Funktionalität erwarten oder in welcher Reihenfolge Sie einzelne Codefragmente schreiben werden.
In diesem Artikel werde ich Sie durch die Erstellung eines Algorithmus für das sogenannte Game of Life führen und dabei gute TDD-Praktiken anwenden.
Die Regeln des Spiels des Lebens
Das Spiel des Lebens wurde vor über einem halben Jahrhundert von dem britischen Mathematiker John Conway erfunden und seine Regeln sind ziemlich einfach.
Das Spiel wird auf einem Brett gespielt, das aus einem Raster besteht, das aus beliebig vielen Feldern besteht, die wir Zellen nennen werden. Jede Zelle kann lebendig (mit Farbe gefüllt) oder tot (leer) sein. Die Zellen, die sie umgeben, sind ihre Nachbarn. Während des Spiels, während das „Leben weitergeht“, geschehen sogenannte Ticks - die Zellen wechseln ihren Zustand gemäß den folgenden Regeln:
- eine lebende Zelle mit weniger als 2 Nachbarn stirbt,
- eine lebende Zelle mit 2 lebenden Nachbarn überlebt,
- eine lebende Zelle mit 3 lebenden Nachbarn überlebt,
- eine lebende Zelle mit mehr als 3 lebenden Nachbarn stirbt,
- eine tote Zelle mit 3 lebenden Nachbarn wird lebendig.
Die Aufgabe des Spielers ist es, die Anordnung der Zellen vor dem ersten Tick zu gestalten.
Nachfolgend ein Beispiel, das den Verlauf des Spiels auf einem Musterbrett veranschaulicht.

In unserer Implementierung wird der Zustand unseres Brettes in einer Tabelle von Tabellen gespeichert, wobei die Indizes der Haupttabelle die Reihen des Brettes widerspiegeln und die Indizes der Untertabellen darin die Spalten (spezifische Zellen) des Brettes widerspiegeln.
TDD - Mach es richtig oder gar nicht
Beginnen Sie mit der Geschäftslogik
Tests müssen nicht (und sollten oft nicht) in der Reihenfolge geschrieben werden, in der das Programm ausgeführt wird. Am Beispiel des Game of Life könnte man denken, dass es sinnvoll wäre, die Funktionen zuerst zu testen, die der Benutzer als erstes in der Anwendung nutzt, wie die Auswahl der Größe des Boards (oder, falls es keine solche Option gibt, einfach die Anzeige). In TDD beginnen wir jedoch mit der Geschäftslogik selbst, die für den Betrieb der Anwendung entscheidend ist.
Testen Sie nur, was notwendig ist
Der erste Schritt wird eine gründliche Analyse der Geschäftslogik und die Planung der ersten kleinen Schritte zur Erstellung einer Anwendung sein. Es ist auch sinnvoll, allgemeine Annahmen über die Anwendung zu treffen, bevor Tests geschrieben werden (wie die Verwendung eines Arrays von Arrays), die unsere Tests und deren Implementierungen auf den richtigen Weg lenken werden. Bei jedem Schritt sollten Sie überlegen, woraus es tatsächlich besteht.
Wenn wir die Testseite betrachten, sollten wir sorgfältig darüber nachdenken, was zu Beginn getestet werden sollte. In unserer Anwendung arbeiten wir mit einem Board beliebiger Größe. Daher lassen Sie uns die folgenden Fragen betrachten:
- Mußten wir das Verhalten von Zellen auf Boards unterschiedlicher Größen testen?
- Wie unterscheiden sich einzelne Zellen?
Nach Überlegungen können wir zu dem Schluss kommen, dass die Geschäftslogik sowohl für die 1x1-, 5x5-, 20x20-Tabelle als auch für jede andere Größe in einer 3x3-Tabelle zusammengefasst werden kann, da sie die Fälle jeder Zelle unabhängig von ihrer Position und der Anzahl der Nachbarn umfasst. Das 3x3-Board wird die mittlere Zelle mit der maximalen Anzahl von 8 Nachbarn enthalten, sowie Zellen an den Rändern und Ecken des Boards.
Bleiben Sie beim Rot-Grün-Refactor-Zyklus
In TDD bauen wir den Code in kleinen Schritten, basierend auf dem Rot-Grün-Refactor-Muster. Dies kann schwierig sein, insbesondere wenn wir bereits die Funktionsweise der gesamten Anwendung kennen und denken, dass es einfacher sein wird, einen Test zu schreiben, der etwas komplexere Funktionalitäten abdeckt. Allerdings lohnt es sich, an den TDD-Annahmen festzuhalten, wenn wir von seinen Vorteilen profitieren wollen, wie dem Schutz vor dem Schreiben redundanten Codes.
Rote Phase — Zwingen Sie sich zum Scheitern
In der roten Phase schreiben wir immer einen Test, der nicht bestanden werden soll, was anfangs unangenehm sein kann. Der Test sollte auch so einfach wie möglich sein und nur den notwendigen Code enthalten. Beim Schreiben ist es gut, einen Plan für weitere Tests im Hinterkopf zu haben. Lassen Sie uns auch auf den Namen achten, der präzise genug sein sollte, damit wir potenziell sofort wissen, welcher Test fehlgeschlagen ist.
Wir entscheiden, dass der erste Test unserer Anwendung überprüfen wird, ob die leere Tabelle nach dem "Tick" leer bleibt. Wir gehen auch davon aus, dass die Implementierung die Board-Klasse erstellt, wobei der aktuelle Zustand des Boards als Parameter übergeben wird. Dann können wir mit dem Schreiben unseres ersten Tests fortfahren (wir werden Jest für die Tests verwenden):
Grüne Phase – lass es nur so funktionieren, wie es sollte
In der grünen Phase implementieren wir eine gegebene Funktionalität auf die einfachste mögliche Weise – der Code muss noch nicht perfekt sein, daher achten wir noch nicht auf die Details. Wir schreiben ihn so, dass er nicht vorweg läuft und das abdeckt, was in späteren Phasen der Anwendungsentwicklung passieren wird. Es ist auch wichtig zu beachten, dass ein gut geschriebener Test viele verschiedene Implementierungen haben kann.
In der grünen Phase überprüfen alle anderen bereits geschriebenen Tests, ob Änderungen an einem bestimmten Ort dazu geführt haben, dass der Fehler an anderer Stelle aufgetreten ist.
Obwohl die Implementierung des Codes für unseren ersten Test sehr einfach sein wird, ist es bereits in dieser Phase sinnvoll, darüber nachzudenken, welche nächsten Schritte wir unternehmen werden und welchen Einfluss diese Lösung auf sie haben wird.
Betrachten wir das folgende Beispiel, in dem wir schließlich eine Board-Klasse erstellen, die eine tick-Methode hat, die die Zellen auf dem Board in die nächste Lebensphase überführt:
Der nächste Schritt könnte z.B. sein, den Fall zu überprüfen, in dem wir das Spiel mit einer lebenden Zelle beginnen, die nach einem Tick sterben sollte. Lassen Sie uns also den zweiten Test schreiben:
Theoretisch ist alles in Ordnung, der Test besteht, also scheint die vorherige Implementierung in Ordnung zu sein. Im Kontext von TDD ist das jedoch leider nicht der Fall. Unser zweiter Test ist jetzt erfolgreich, obwohl wir nach dem Schreiben keine Implementierungsänderungen vorgenommen haben. Das bedeutet, dass unser Code ein bisschen zu viel Funktionalität abdeckt und wir ihn anpassen sollten, damit er sich so präzise wie möglich nur auf den zu entwickelnden Testfall (den ersten Test mit einem leeren Board) bezieht. Eine bessere Lösung wäre hier wie folgt:
Mit dieser Implementierung besteht unser erster Test, aber der zweite schlägt fehl.
Und jetzt ist es endlich an der Zeit, eine Implementierung einzuführen, bei der der zweite Test besteht, und das könnte dieselbe sein, bei der die tick-Methode ein leeres Array zurückgibt. So rückwärts zu gehen, mag wie Zeitverschwendung erscheinen, da wir letztendlich dieselbe Implementierung schreiben. Es beinhaltet jedoch ein tiefes Verständnis dafür, wie unser Code funktioniert, und entspricht den Annahmen von TDD. Betrachten Sie es so: Wenn wir den nächsten Test im Voraus geplant hätten (wie TDD sagt), hätten wir Situationen dieser Art vermeiden können, da wir es im Hinterkopf gehabt hätten, als wir unser erstes Implementierungsfragment geschrieben haben.
Refactor-Phase — Zeit zum Aufräumen
In der Refactor-Phase säubern wir den bestehenden Code und passen ihn an den aktuellen Stand des Programms an. Wir können Änderungen am gesamten bestehenden Code vornehmen, ohne uns Sorgen machen zu müssen, etwas zu beschädigen - wir haben schließlich Tests für jede Codezeile geschrieben.
Dann beginnen wir den Zyklus von vorne, bis wir das Ziel einer voll funktionsfähigen Anwendung erreicht haben.
Gehe Schritt für Schritt weiter, ohne an den ursprünglichen Annahmen festzuhalten - analysiere aktuell und erlaube dir, deinen Plan zu ändern
Schließlich ist es an der Zeit, einige der komplizierteren Anordnungen von Zellen auf dem Board zu testen, als nur eine lebende Zelle, die nach einem Tick stirbt. Die Entscheidung, ob wir die Funktionsweise des Algorithmus separat für jeden Typ von Zellstandort auf dem Board überprüfen oder ob wir das gesamte Board auf einmal testen, ist eine Frage der Vorlieben eines Programmierers. Wir müssen entscheiden, ob der Fall jeder Zelle für uns so besonders ist, dass es sich lohnt, 9 individuelle Tests und deren Implementierungen zu schreiben, einen für jede von ihnen. Im folgenden Beispiel haben wir uns entschieden, das gesamte Board gleichzeitig zu testen. Zu diesem Zweck werden wir einige verschiedene Beispiel-Boards vor und nach dem Tick testen:
Okay, wir haben einen Test (der natürlich nicht bestanden wird), also ist es Zeit, die Implementierung dafür zu schreiben… Aber wo fangen wir an? Lassen Sie uns sehen, was wir hier wirklich codieren müssen. Damit der obige Test besteht, müssen wir:
- jede der Zellen irgendwie verfolgen,
- überprüfen, ob eine gegebene Zelle lebendig oder tot ist,
- zählen, wie viele Nachbarn sie lebendig hat,
- alle Regeln bezüglich des Schicksals einer toten oder lebenden Zelle auf sie anwenden,
- alles oben Genannte für jede Zelle auf dem Board tun.
Ups… es sieht so aus, als wäre das eine Menge Arbeit, die wir in nur einem Schritt unseres TDD-Prozesses erledigen müssen. Jetzt betreten wir die Phase der fortgeschritteneren Geschäftslogik unserer Anwendung und versuchen, einen viel komplexeren Fall als zuvor abzudecken. Wollen wir all diese Dinge auf einmal tun? Oder sollten wir vielleicht unseren Aktionsplan überdenken? Lassen Sie uns überlegen: Wollen wir zu diesem Zeitpunkt wirklich weiterhin das gesamte Board testen? Oder gibt es vielleicht eine Möglichkeit, die Komplexität der Tests und des Codes selbst zu reduzieren? War unser ursprünglicher Plan wirklich so gut?
Wenn wir darüber nachdenken, anstatt das Verhalten aller Zellen auf dem Board nach jedem Tick zu testen, könnten wir uns zuerst nur darauf konzentrieren, was mit einer einzelnen, spezifischen Zelle passiert. Dies vereinfacht die Testfälle und deren Implementierungen erheblich. Also haben wir keine Angst, von vorne zu beginnen. Ja - ganz von vorne! Entgegen den Anschein kann uns das viel Zeit sparen. Denken Sie daran: Es lohnt sich nicht, sich auf etwas einzulassen, das sich auch nach langer Arbeit daran als nicht gute Lösung herausstellt.
Es ist ein guter Moment, um die neue .failing-Funktion von Jest zu nutzen. Damit können wir einen Test erstellen, der tatsächlich abstürzt, bestehen lassen. Es ist nützlich in Situationen, in denen wir möchten, dass ein gegebener Test für eine gewisse Zeit nicht besteht, aber später erfolgreich ist. Wir können unseren Test einfach in unserem Testcode belassen, ohne die .skip-Funktion zu verwenden, damit wir ihn in Zukunft nicht vergessen - wir werden genau sehen, wann die fortschreitende Implementierung unseres Codes den Fall aus diesem genauen Test abdeckt - er wird dann einfach abstürzen. Also lassen Sie uns das nutzen:
Die .failing-Methode funktioniert nicht zusammen mit der .each-Methode (und das ist eine bewusste Absicht ihres Schöpfers, da das Schreiben vieler fehlschlagender Tests auf einmal in einem Test das Ziel dieser Funktion etwas verfehlen würde), sodass jeder Fall in einem separaten Test getestet wird. Denken Sie daran, dass die .failing-Funktion nur funktioniert, wenn Sie mindestens Version 28.1.0 von Jest und Version 28.0.1 von ts-jest verwenden. Unten finden Sie ein Beispiel für die richtigen devDependencies in package.json:
Wie Sie sehen können, bestehen die obigen Tests:
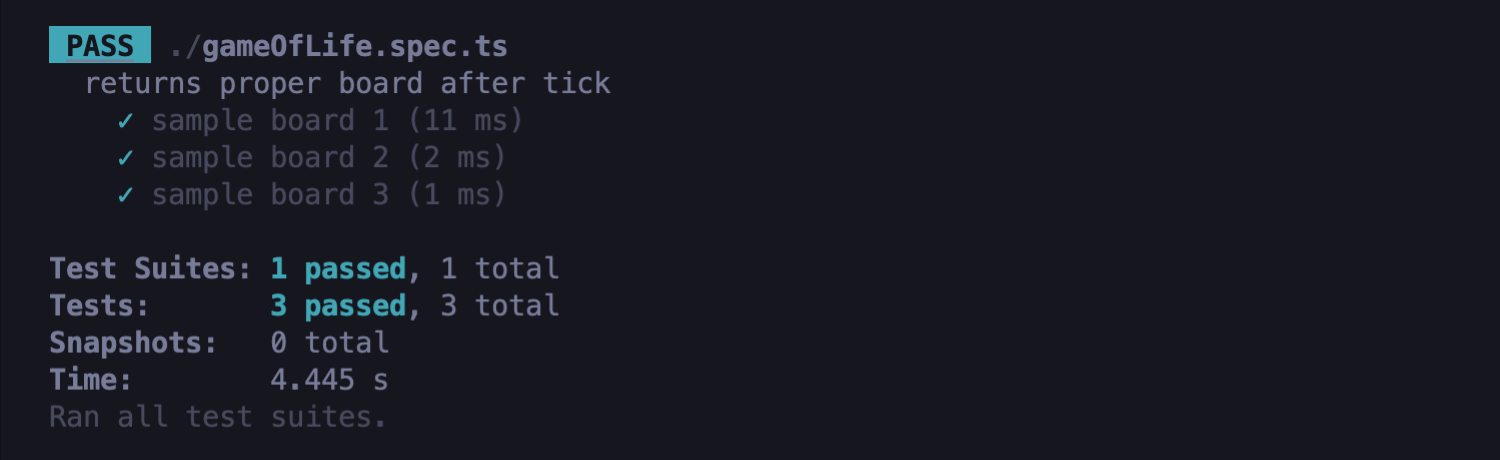
- Hier können Sie mehr über die .failing-Funktion lesen: test.failing.
Jetzt ist es an der Zeit herauszufinden, welche Faktoren das Schicksal einer einzelnen Zelle nach jedem Tick bestimmen. Es gibt hier 2 Dinge: ob die Zelle derzeit lebendig oder tot ist und wie viele Nachbarn sie derzeit hat. Wir müssen überlegen, wie wir die Tests planen. Lassen Sie uns zu den Regeln des Spiels zurückkehren:
- eine lebende Zelle mit weniger als 2 Nachbarn stirbt,
- eine lebende Zelle mit 2 lebenden Nachbarn überlebt,
- eine lebende Zelle mit 3 lebenden Nachbarn überlebt,
- eine lebende Zelle mit mehr als 3 lebenden Nachbarn stirbt,
- eine tote Zelle mit 3 lebenden Nachbarn wird lebendig.
Wie viele Testfälle gibt uns das? Müssen wir jede der Regeln separat testen? Oder könnten sie vielleicht irgendwie miteinander kombiniert werden? Nach einer etwas genaueren Analyse der Regeln können wir feststellen, dass:
- jede Zelle mit weniger als 2 Nachbarn, unabhängig davon, ob sie derzeit lebendig oder tot ist, nach einem Tick stirbt,
- jede Zelle mit genau 3 Nachbarn, unabhängig davon, ob sie derzeit lebendig oder tot ist, nach dem "Tick" lebendig sein wird,
- wenn eine Zelle derzeit 2 Nachbarn hat, wird die Zelle nur nach dem Tick lebendig sein, wenn sie bereits lebendig ist.
Und das war's. 3 Testfälle reichen aus, um die gesamte Geschäftslogik eines einzelnen Zellzyklus abzudecken. Das einzige, was jetzt noch zu tun bleibt, ist die Reihenfolge der Tests zu bestimmen, in der jeder folgende zunächst nicht bestehen wird. Wenn wir beispielsweise mit der dritten Anforderung beginnen würden, in der eine lebende Zelle mit 2 Nachbarn überlebt und sonst nicht, würden wir auch die erste Anforderung mit dieser Implementierung abdecken, was wir nicht wollen. Die Reihenfolge, in der sie oben aufgeführt sind, verhindert, dass dies geschieht. Im folgenden Test haben wir angenommen, dass wir eine Klasse Cell erstellen, die 2 Parameter im Konstruktor enthält: den Zustand der Zelle (lebendig - 1 oder tot - 0) und die Anzahl ihrer lebenden Nachbarn. Der erste Test schlägt natürlich fehl, da die Klasse Cell zu diesem Zeitpunkt nicht einmal existiert.
Beim Schreiben der Implementierung denken Sie daran, dass wir möchten, dass sie nicht die Funktionalität abdeckt, die wir in den folgenden Tests testen möchten. Eine Beispielklasse, die eine Methode zum Setzen des Zustands der zu testenden Zelle nach dem "Tick" enthält, würde so aussehen:
Für die zweite Anforderung schreiben wir einen weiteren, analogischen, zunächst fehlgeschlagenen Test:
Und eine Implementierung, die die Tick-Methode ändert:
Und schließlich der Test für die dritte Anforderung:
Mit der Implementierung, die die Tick-Methode ändert:
An diesem Punkt ist der Bedarf, die Lesbarkeit des Codes zu erhöhen, deutlich sichtbar, also gehen wir jetzt in die Refaktorierungsphase über und entscheiden, zusätzliche Methoden in der Cell-Klasse zu erstellen:
Jetzt, da wir wissen, dass der Algorithmus, der für den Betrieb einer einzelnen Zelle verantwortlich ist, korrekt funktioniert, müssen wir überprüfen, ob wir die richtigen Daten in den Konstruktor der Cell-Klasse für jede Zelle auf dem Board eingeben.
Bevor wir mit unserem Ansatz zur Logik einer einzelnen Zelle begonnen haben, haben wir bereits den Test geschrieben, den wir jetzt benötigen - den, in dem wir die .failing-Funktion verwendet haben. Jetzt wird die Implementierung viel weniger kompliziert sein, da wir bereits Dinge wie den Bezug darauf, ob die Zelle lebendig oder tot ist, wie viele Nachbarn sie hat und wie sie sich nach einem Tick verhält, abgedeckt haben. Das Einzige, was noch zu tun bleibt, ist, diese Logik auf das gesamte Board zu übertragen und die Tick-Methode der Cell-Klasse für jedes Feld davon zu verwenden.
Unsere Implementierung nach der grünen und Refactor-Phase sieht wie folgt aus. In diesem Beispiel haben wir das sogenannte Null-Objekt-Muster verwendet, das wir hier nicht näher beschreiben werden, aber kurz gesagt ist es ein Entwurfsmuster, das eine tote Entität wie eine leere behandelt, sodass es nicht notwendig ist, zwischen ihnen zu unterscheiden, und dies wiederum ermöglicht es, zu vermeiden, zu überprüfen, ob ein bestimmter Wert ungleich null ist. Denken Sie jedoch daran, dass ein guter Test es Ihnen ermöglicht, jede Implementierung zu verwenden, die sich voneinander unterscheidet, sodass die untenstehende nicht die einzige korrekte ist:
An diesem Punkt können wir sehen, dass unsere Tests des gesamten Boards endlich fehlgeschlagen sind:
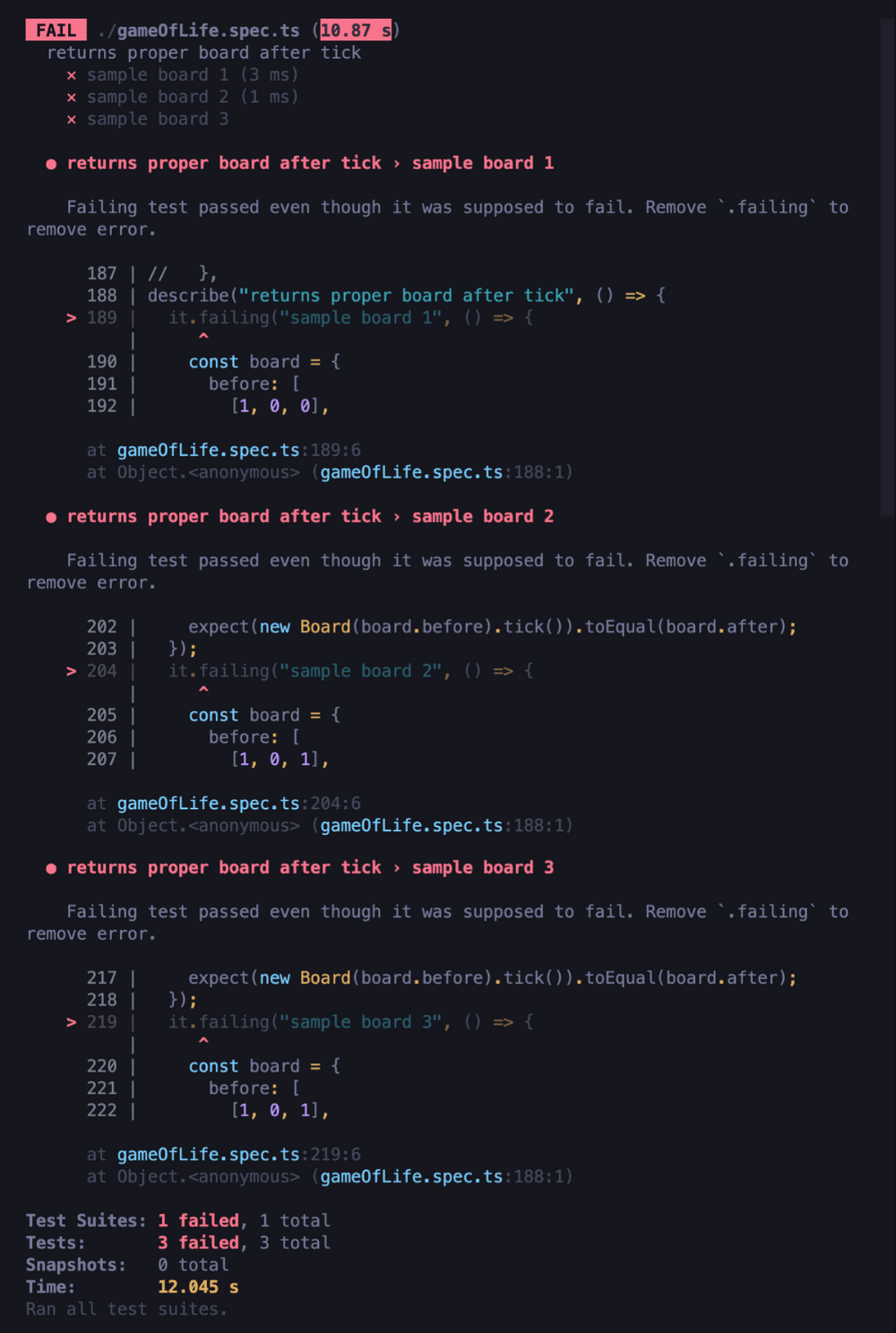
Jetzt müssen wir nur noch die .failing-Methode aus allen oben genannten Tests entfernen. Sie alle erweisen sich als bestanden, sodass wir mit Sicherheit sagen können, dass wir unsere Arbeit erfolgreich abgeschlossen haben.
Was uns TDD gegeben hat?
TDD gibt uns in erster Linie die Möglichkeit, Stück für Stück funktionierenden Code zu schreiben und diesen während des Entwicklungs- und Refactoring-Prozesses zu kontrollieren, dank der 100%igen Codeabdeckung.
TDD verändert auch den Ansatz zum Programmieren selbst. Bei der Anwendung kämpfen wir hauptsächlich damit, die geschäftlichen Annahmen abzudecken und nicht mit Problemen, die aus dem Code selbst entstehen. Dies gibt uns die Chance (oder zwingt uns sogar), eine gründliche Analyse der Anforderungen vorzunehmen und diese während des Anwendungsentwicklungsprozesses ständig zu überprüfen, was, wie im obigen Beispiel des Game of Life dargestellt, uns davor bewahren kann, viel überflüssigen Code zu schreiben.
Obwohl TDD noch nicht alle überzeugt und manchmal von vielen Entwicklern, die es zuvor nicht verwendet haben, als Zeitverschwendung angesehen wird, lohnt es sich - modisch gesprochen - aus der Komfortzone herauszukommen und zu versuchen, es in der täglichen Arbeit anzuwenden, denn die anfänglichen Qualen bei der Anwendung werden letztendlich in effizienteres Arbeiten, bessere Codequalität und viel weniger Frustration bei der Fehlersuche im Code umschlagen.
Siehe auch
- Wie man Core Web Vitals mit Next.js verbessert? — Next.js bietet uns hybride statische & serverseitige Renderings, automatisches Code-Splitting, Bildoptimierung und mehr, während es relativ einfach zu erlernen ist. Sie können die Core Web Vitals einfach verbessern, indem Sie es richtig nutzen.
Vielleicht gefällt Ihnen auch
FigJam vs. Miro: Welches Kollaborationstool ist das Richtige für Ihr Team?
7 März 2025 • Maria Pradiuszyk
Navigieren durch die digitale Transformation in der Medien- und Unterhaltungsbranche
7 März 2025 • Maria Pradiuszyk

React Native: Wie man Apps in verschiedenen Umgebungen bereitstellt und testet?
7 März 2025 • Agnieszka Łobocka
Wir sind für neue Projekte verfügbar.
