
Chapters

Programiści używają TDD, aby zadbać o jakość i niezawodność kodu, który tworzą, oraz aby poprawić proces jego tworzenia. Jednak nie zawsze zwracają uwagę na to, że samo pisanie testów może być mniej lub bardziej optymalne.
TDD (Test Driven Development) zakłada, że zaczynasz pisać kod, tworząc testy, które spełniają wymagania logiki biznesowej, a następnie tworzysz ich implementacje w kodzie aplikacji. To założenie wydaje się proste, ale aby podejście to przyniosło jak najwięcej korzyści i optymalizowało, zamiast utrudniać proces, powinieneś trzymać się jego zasad i myśleć o takich rzeczach jak co tak naprawdę chcesz przetestować, co wymagasz od danej funkcjonalności lub w jakiej kolejności będziesz pisać poszczególne fragmenty kodu.
W tym artykule przeprowadzę cię przez tworzenie algorytmu dla tzw. Gry w Życie, stosując dobre praktyki TDD.
Reguły Gry w Życie
Gra w Życie została wynaleziona ponad pół wieku temu przez brytyjskiego matematyka Johna Conwaya, a jej zasady są dość proste.
Gra toczy się na planszy, która jest siatką składającą się z dowolnej liczby kwadratów, które nazwiemy komórkami. Każda komórka może być żywa (wypełniona kolorem) lub martwa (pusta). Komórki, które ją otaczają, to jej sąsiedzi. Podczas gry, gdy „życie toczy się dalej”, mają miejsce tzw. tyknięcia - komórki przechodzą do swojego następnego stanu zgodnie z następującymi zasadami:
- żywa komórka z mniej niż 2 sąsiadami umiera,
- żywa komórka z 2 żywymi sąsiadami przetrwa,
- żywa komórka z 3 żywymi sąsiadami przetrwa,
- żywa komórka z więcej niż 3 żywymi sąsiadami umiera,
- martwa komórka z 3 żywymi sąsiadami ożywa.
Rolą gracza jest zaprojektowanie układu komórek przed pierwszym tyknięciem.
Poniżej znajduje się przykład ilustrujący przebieg gry na przykładowej planszy.

W naszej implementacji stan naszej planszy będzie przechowywany w tabeli tabel, gdzie indeksy głównej tabeli będą odzwierciedlać wiersze planszy, a indeksy podtabel w niej będą odzwierciedlać kolumny (konkretne komórki) planszy.
TDD - rób to dobrze lub wcale
Rozpocznij od logiki biznesowej
Testy nie muszą (i często nie powinny) być pisane w kolejności, w jakiej program będzie działał. Używając przykładu Gry w Życie, możesz pomyśleć, że jeśli pierwszą rzeczą, którą użytkownik robi w aplikacji, jest wybór rozmiaru planszy (lub jeśli nie ma takiej opcji, to po prostu jej wyświetlenie), to odpowiednie byłoby najpierw przetestować takie funkcjonalności. W TDD jednak zaczynamy od samej logiki biznesowej, która jest kluczowa dla działania aplikacji.
Testuj tylko to, co konieczne
Pierwszym krokiem będzie dokładna analiza logiki biznesowej i zaplanowanie początkowych małych kroków tworzenia aplikacji. Warto również sformułować ogólne założenia aplikacji przed napisaniem testów (takie jak użycie tablicy tablic), co skieruje nasze testy i ich implementacje na właściwą ścieżkę. Na każdym etapie należy zastanowić się, z czego właściwie to się składa.
Patrząc na stronę testowania, powinniśmy dokładnie przemyśleć, co powinno być testowane na samym początku. W naszej aplikacji pracujemy na planszy o dowolnym rozmiarze. Zatem rozważmy następujące kwestie:
- Czy musimy testować zachowanie komórek na planszach o różnych rozmiarach?
- Jak różnią się poszczególne komórki?
Po refleksji możemy dojść do wniosku, że logika biznesowa zarówno dla tabeli 1x1, 5x5, 20x20, jak i dowolnego innego rozmiaru może być zamknięta w tabeli 3x3, ponieważ obejmuje przypadki każdej komórki, niezależnie od jej lokalizacji i liczby sąsiadów. Plansza 3x3 będzie zawierać środkową komórkę z maksymalną liczbą 8 sąsiadów, a także komórki na krawędziach i rogach planszy.
Trzymaj się pętli red-green-refactor
W TDD budujemy kod w małych krokach, opierając się na wzorcu red-green-refactor. Może to być trudne, szczególnie jeśli już znamy działanie całej aplikacji i możemy pomyśleć, że łatwiej będzie napisać test, który pokryje nieco bardziej złożone funkcjonalności. Jednak warto trzymać się założeń TDD, jeśli chcemy skorzystać z jego zalet, takich jak ochrona przed pisaniem zbędnego kodu.
Czerwona faza — zmuszaj się do porażki
W czerwonej fazie zawsze piszemy test, który nie ma być zaliczony, co może być na początku niewygodne. Test powinien być również jak najprostszy i zawierać tylko niezbędny kod. Pisząc go, dobrze jest mieć w głowie plan dalszych testów. Zwróćmy również uwagę na nazwę, która powinna być na tyle precyzyjna, abyśmy potencjalnie mogli od razu wiedzieć, który test nie przeszedł.
Decydujemy, że pierwszy test naszej aplikacji sprawdzi, czy pusta tabela po "tyknięciu" pozostanie pusta. Zakładamy również, że implementacja stworzy klasę Board, przyjmując aktualny stan planszy jako parametr. Następnie możemy przystąpić do pisania naszego pierwszego testu (użyjemy Jest do testowania):
Faza zielona — niech działa tylko tak, jak powinna
W fazie zielonej wdrażamy daną funkcjonalność w jak najprostszy sposób - nie musi to być jeszcze perfekcyjny kod, więc na szczegóły nie zwracamy uwagi. Pisujemy go tak, aby nie wyprzedzał tego, co wydarzy się w późniejszych etapach rozwoju aplikacji. Warto również pamiętać, że dobrze napisany test może mieć wiele różnych implementacji.
W fazie zielonej wszystkie inne już napisane testy sprawdzają, czy zmiany w danym miejscu spowodowały wystąpienie błędu gdzie indziej.
Chociaż implementacja kodu dla naszego pierwszego testu będzie bardzo prosta, już na tym etapie warto rozważyć, jakie będą nasze następne kroki i jaki wpływ to rozwiązanie będzie miało na nie.
Rozważmy poniższy przykład, w którym ostatecznie tworzymy klasę Board, która ma metodę tick, która przenosi komórki na planszy do następnego etapu życia:
Następnym krokiem może być np. sprawdzenie przypadku, w którym zaczynamy grę z jedną żywą komórką, która powinna umrzeć po ticku. Zatem napiszmy drugi test:
Teoretycznie wszystko jest w porządku, test przechodzi, więc wcześniejsza implementacja wydaje się w porządku. Jednak w kontekście TDD, niestety tak nie jest. Nasz drugi test jest teraz udany, mimo że nie wprowadziliśmy żadnych zmian w implementacji po jego napisaniu. Oznacza to, że nasz kod obejmuje nieco zbyt wiele funkcjonalności i powinniśmy go dostosować, aby odnosił się jak najdokładniej tylko do przypadku testowego, nad którym pracujemy (pierwszy test z pustą planszą). Lepszym rozwiązaniem tutaj będzie takie jak poniżej:
Z tą implementacją nasz pierwszy test jest zaliczony, ale drugi jest niezaliczony.
A teraz nadszedł czas, aby wprowadzić implementację, w której drugi test przechodzi, a mogłaby to być ta sama, w której metoda tick zwraca pustą tablicę. Takie cofanie się może wydawać się stratą czasu, ponieważ w końcu i tak piszemy tę samą implementację. Jednak wiąże się to z głębokim zrozumieniem, jak działa nasz kod i spełnia założenia TDD. Patrz na to w ten sposób: gdybyśmy zaplanowali następny test z wyprzedzeniem (jak mówi TDD), moglibyśmy uniknąć takich sytuacji, ponieważ mielibyśmy to z tyłu głowy podczas pisania fragmentu naszej pierwszej implementacji.
Faza refaktoryzacji — czas na porządki
W fazie refaktoryzacji czyścimy istniejący kod i dostosowujemy go do aktualnego stanu programu. Możemy wprowadzać zmiany w całym istniejącym kodzie, nie martwiąc się o to, że coś się zepsuje - w końcu mamy testy dla każdej linii napisanego kodu.
Następnie zaczynamy cykl od nowa, aż osiągniemy cel pełnej zakładanej funkcjonalności naszej aplikacji.
Idź dalej krok po kroku, nie trzymając się początkowych założeń - analizuj na bieżąco i pozwól sobie na zmianę planu
W końcu nadszedł czas, aby przetestować niektóre z bardziej skomplikowanych układów komórek na planszy niż tylko jedna żyjąca komórka umierająca po ticku. Decyzja, czy sprawdzamy działanie algorytmu osobno dla każdego typu lokalizacji komórki na planszy, czy testujemy całą planszę jednocześnie, zależy od preferencji programisty. Musimy zdecydować, czy przypadek każdej komórki jest dla nas na tyle szczególny, że warto napisać 9 indywidualnych testów i ich implementacji, po jednym dla każdej z nich. W poniższym przykładzie zdecydowaliśmy się przetestować całą planszę jednocześnie. W tym celu przetestujemy kilka różnych przykładowych plansz przed i po ticku:
Ok, mamy test (który oczywiście nie przeszedł), więc czas napisać do niego implementację… Ale od czego zacząć? Zobaczmy, co naprawdę musimy zakodować tutaj. Aby powyższy test przeszedł, musimy:
- śledzić każdą z komórek w jakiś sposób,
- sprawdzić, czy dana komórka jest żywa, czy martwa,
- policzyć, ilu sąsiadów jest żywych,
- zastosować wszystkie zasady dotyczące losu martwej lub żyjącej komórki,
- zrobić to wszystko dla każdej komórki na planszy.
Ups… wygląda na to, że to DUŻO pracy do zrobienia w zaledwie jednym kroku naszego procesu TDD. Teraz wchodzimy w etap bardziej zaawansowanej logiki biznesowej naszej aplikacji i próbujemy pokryć znacznie bardziej złożony przypadek niż wcześniej. Czy chcemy robić to wszystko naraz? A może powinniśmy przemyśleć nasz plan działania? Pomyślmy: czy na pewno chcemy kontynuować testowanie całej planszy w tym momencie? A może jest sposób, aby zmniejszyć złożoność testów i samego kodu? Czy nasz pierwotny plan był na pewno tak dobry?
Jeśli się nad tym zastanowimy, zamiast testować zachowanie wszystkich komórek na planszy po każdym ticku, moglibyśmy najpierw skupić się na tym, co dzieje się z jedną, konkretną komórką. To znacznie upraszcza przypadki testowe i ich implementacje. Nie bójmy się więc zacząć od nowa. Tak - od nowa! Wbrew pozorom, może to zaoszczędzić nam dużo czasu. Pamiętaj: nie warto wchodzić w coś, co okazuje się nie być dobrym rozwiązaniem nawet po długim czasie pracy nad tym.
To dobry moment, aby skorzystać z nowej funkcji .failing w Jest. Dzięki niej możemy sprawić, że test, który faktycznie się nie powiódł, przejdzie. Jest to przydatne w sytuacjach, gdy chcemy, aby dany test przez jakiś czas nie przeszedł, ale później odniósł sukces. Możemy po prostu zostawić nasz test w kodzie testowym, nie używając funkcji .skip, aby nie zapomnieć o nim w przyszłości - zobaczymy dokładnie, kiedy postępująca implementacja naszego kodu pokryje przypadek z tego konkretnego testu - po prostu wtedy się nie powiedzie. Więc użyjmy tego:
Metoda .failing nie działa razem z metodą .each (i jest to zamierzona intencja jej twórcy, ponieważ pisanie wielu nieudanych testów naraz w jednym teście nieco mijałoby cel tej funkcji), więc każdy przypadek będzie testowany w osobnym teście. Pamiętaj, że aby funkcja .failing działała, musisz używać co najmniej wersji 28.1.0 Jest i wersji 28.0.1 ts-jest. Poniżej znajduje się przykład odpowiednich devDependencies w package.json:
Jak widać, powyższe testy przeszły:
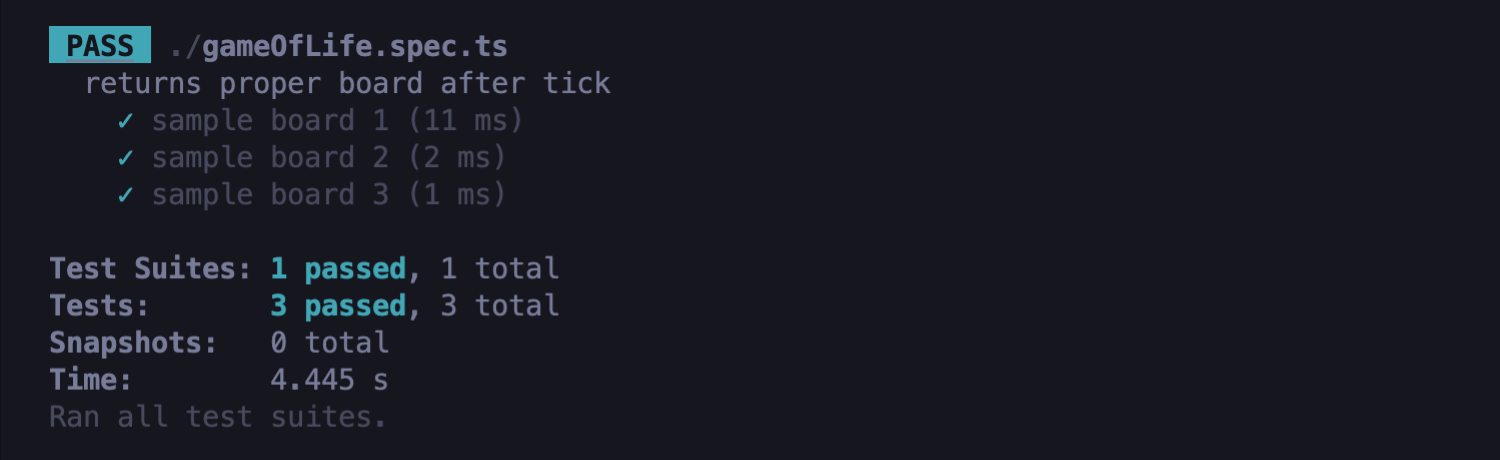
- Tutaj możesz przeczytać więcej o funkcji .failing: test.failing.
Teraz nadszedł czas, aby dowiedzieć się, jakie czynniki decydują o losie pojedynczej komórki po każdym ticku. Są dwie rzeczy: czy komórka jest obecnie żywa, czy martwa, oraz ilu sąsiadów obecnie ma. Musimy rozważyć, jak zaplanować testy. Wróćmy do zasad gry:
- żyjąca komórka z mniej niż 2 sąsiadami umiera,
- żyjąca komórka z 2 żywymi sąsiadami przeżywa,
- żyjąca komórka z 3 żywymi sąsiadami przeżywa,
- żyjąca komórka z więcej niż 3 żywymi sąsiadami umiera,
- martwa komórka z 3 żywymi sąsiadami ożywa.
Ile przypadków testowych to nam daje? Czy musimy testować każdą z zasad osobno? A może mogłyby one jakoś się ze sobą połączyć? Po dokładniejszej analizie zasad możemy ustalić, że:
- każda komórka z mniej niż 2 sąsiadami, niezależnie od tego, czy jest obecnie żywa, czy martwa, umrze po ticku,
- każda komórka z dokładnie 3 sąsiadami, niezależnie od tego, czy jest obecnie żywa, czy martwa, będzie żywa po "ticku",
- jeśli komórka obecnie ma 2 sąsiadów, komórka będzie żywa po ticku tylko wtedy, gdy już jest żywa.
I to wszystko. 3 przypadki testowe wystarczą, aby pokryć całą logikę biznesową cyklu życia pojedynczej komórki. Jedyną rzeczą, którą teraz musimy zrobić, jest określenie kolejności testów, w której każdy kolejny nie przejdzie początkowo. Jeśli na przykład zaczęlibyśmy od trzeciego wymogu, w którym żyjąca komórka z 2 sąsiadami przeżywa, a w przeciwnym razie nie, pokrylibyśmy również pierwszy wymóg tą implementacją, czego nie chcemy. Kolejność, w jakiej są wymienione powyżej, zapobiega temu, aby to się stało. W następnym teście założyliśmy, że stworzymy klasę Cell zawierającą 2 parametry w konstruktorze: stan komórki (żywa - 1 lub martwa - 0) oraz liczbę jej żywych sąsiadów. Pierwszy test oczywiście nie przechodzi, ponieważ klasa Cell nawet nie istnieje na tym etapie.
Pisząc implementację, pamiętaj, że chcemy, aby nie pokrywała funkcjonalności, którą chcemy testować w kolejnych testach. Przykładowa klasa zawierająca metodę do ustawiania stanu komórki testowej po "ticku" wyglądałaby tak:
Dla drugiego wymogu piszemy kolejny, analogiczny, początkowo nieudany test:
I implementację, która zmienia metodę tick:
I w końcu test dla trzeciego wymogu:
Z implementacją modyfikującą metodę tick:
Na tym etapie wyraźnie widać potrzebę zwiększenia czytelności kodu, więc teraz przechodzimy do fazy refaktoryzacji, decydując się na stworzenie dodatkowych metod w klasie Cell:
Stwórzmy w końcu całą tablicę z komórek
Musimy zastosować metody, które klasa Cell nam daje, do planszy, którą opiszemy (jak wcześniej, przed zmianą planu działania) za pomocą klasy Board.
Grupowanie testów w celu zwiększenia czytelności
Naprawdę warto nieco uporządkować nasze testy. Oprócz zebrania ich wszystkich w jednym "describe", np. "Gra w życie", dobrze byłoby również użyć zagnieżdżonych opisów dla klas "Cell" i "Board". Wprowadzamy takie usprawnienia w jednej z faz refaktoryzacji (im szybciej, tym lepiej). W efekcie będzie to wyglądać mniej więcej tak:
Teraz, gdy wiemy, że algorytm odpowiedzialny za działanie pojedynczej komórki działa poprawnie, musimy sprawdzić, czy wprowadzimy poprawne dane do konstruktora klasy Cell dla każdej komórki na planszy.
Przed rozpoczęciem naszego podejścia do logiki pojedynczej komórki, już napisaliśmy test, którego teraz potrzebujemy - ten, w którym użyliśmy funkcji .failing. Teraz jego implementacja będzie znacznie mniej skomplikowana, ponieważ już udało nam się pokryć takie aspekty jak odniesienie do tego, czy komórka jest żywa czy martwa, ilu ma sąsiadów oraz jak będzie się zachowywać po ticku. Jedyną rzeczą, którą musimy zrobić, jest przeniesienie tej logiki na całą planszę i użycie metody tick klasy Cell dla każdego pola na niej.
Nasza implementacja po fazie zielonej i refaktoryzacji wygląda jak poniżej. W tym przykładzie użyliśmy tzw. wzorca obiektu null, którego nie będziemy opisywać bardziej szczegółowo, ale w skrócie jest to wzorzec projektowy, który sprawia, że martwa jednostka zachowuje się jak pusta, więc nie ma potrzeby rozróżniania ich, co z kolei pozwala uniknąć sprawdzania, czy dana wartość różni się od null. Pamiętaj jednak, że dobry test pozwala na użycie dowolnej implementacji, która różni się od siebie, więc ta poniżej nie jest jedyną poprawną:
W tym momencie widzimy, że nasze testy całej planszy w końcu się nie powiodły:
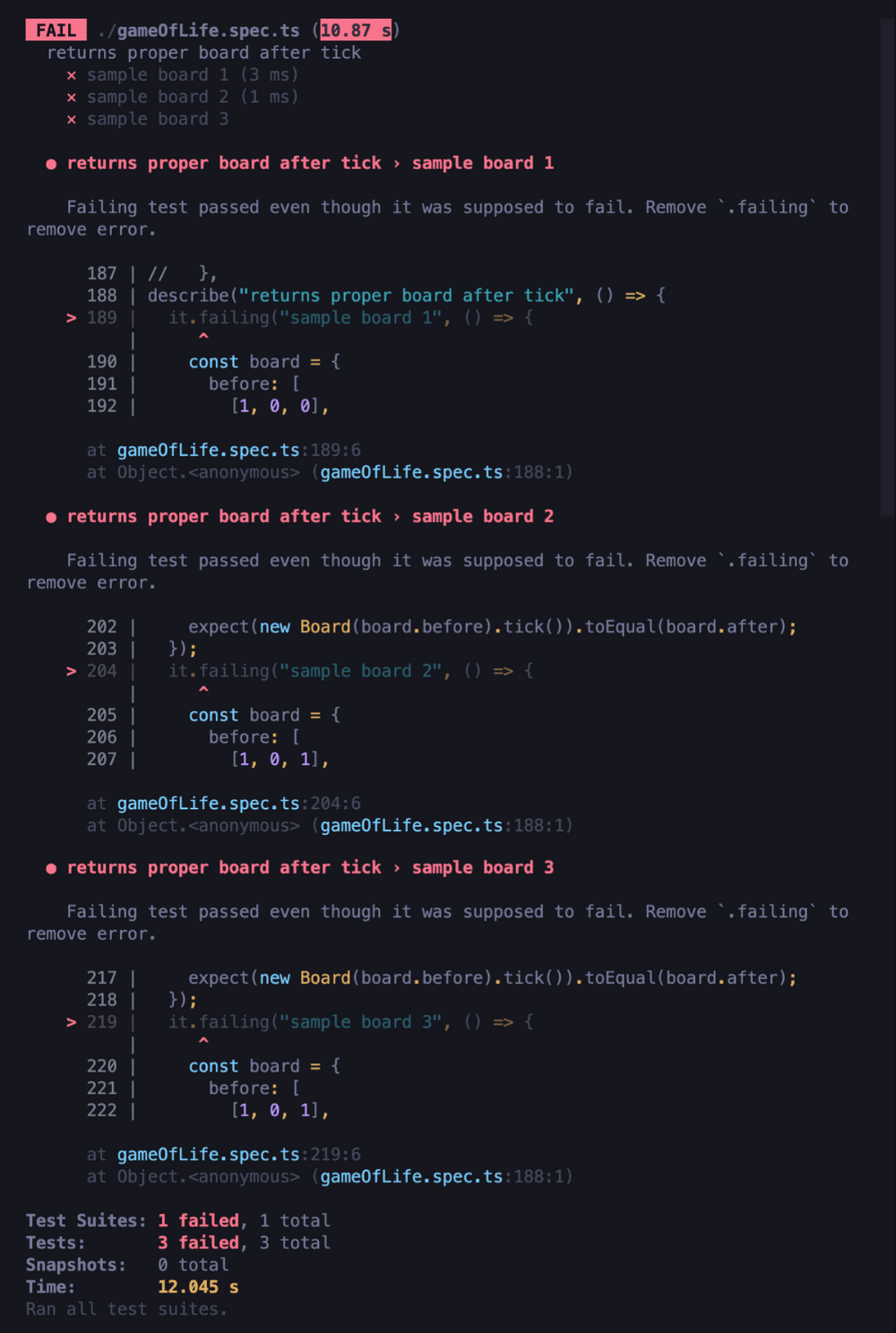
Teraz musimy tylko usunąć metodę .failing ze wszystkich powyższych testów. Okazuje się, że wszystkie przechodzą, więc możemy śmiało powiedzieć, że pomyślnie zakończyliśmy naszą pracę.
Co dało nam TDD?
TDD przede wszystkim daje nam możliwość pisania kodu działającego kawałek po kawałku i kontrolowania go w trakcie procesu rozwoju i refaktoryzacji, dzięki 100% pokryciu kodu.
TDD zmienia również podejście do samego programowania. Korzystając z niego, zmagamy się przede wszystkim z pokrywaniem założeń biznesowych, a nie z problemami wynikającymi z samego kodu. Daje nam to szansę (a nawet zmusza) do dokładnej analizy wymagań i stałej weryfikacji ich w trakcie procesu rozwoju aplikacji, co, jak pokazano w powyższym przykładzie Gry w Życie, może uchronić cię przed napisaniem dużej ilości zbędnego kodu.
Chociaż TDD wciąż nie przekonuje wszystkich i czasami jest uważane za stratę czasu wśród wielu programistów, którzy wcześniej go nie stosowali, warto - mówiąc modnie - wyjść ze strefy komfortu i spróbować zastosować to w swojej codziennej pracy, ponieważ początkowe męki związane z jego używaniem ostatecznie przekształcą się w bardziej efektywną pracę, lepszą jakość kodu i znacznie mniej frustracji związanej z szukaniem błędów w swoim kodzie.
Sprawdź także
- Jak poprawić Core Web Vitals używając Next.js? — Next.js oferuje hybrydowe renderowanie statyczne i serwerowe, automatyczne dzielenie kodu, optymalizację obrazów i wiele więcej, a jednocześnie jest stosunkowo łatwy do nauki. Możesz poprawić Core Web Vitals, po prostu używając go w odpowiedni sposób.
Może Ci się również spodobać

Dlaczego dramat związany z WordPress sprawia, że przejście na Webflow to mądry krok
11 marca 2025 • Maria Pradiuszyk


Jak przeprowadzić warsztat odkrywczo-badawczy: przewodnik krok po kroku
11 marca 2025 • Maria Pradiuszyk
Jesteśmy dostępni dla nowych projektów.
